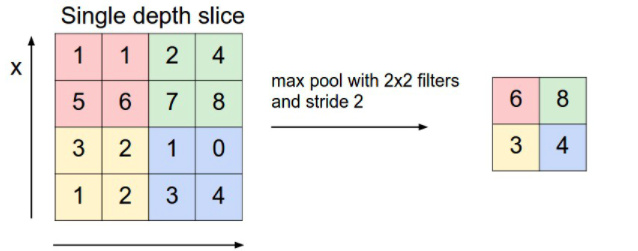
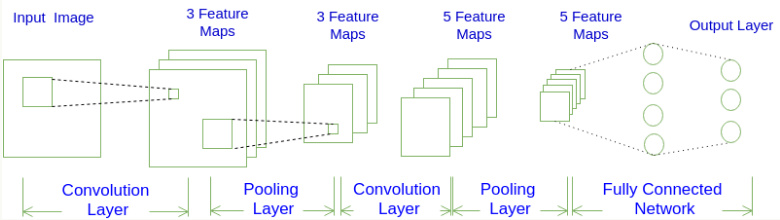
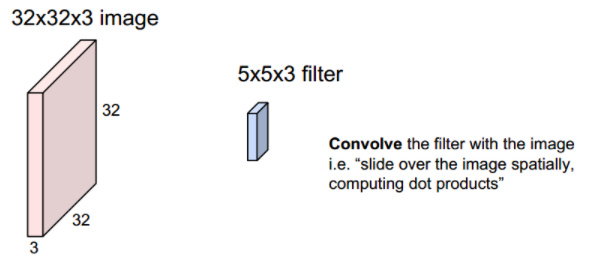
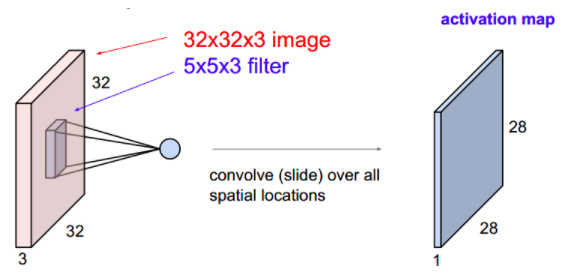
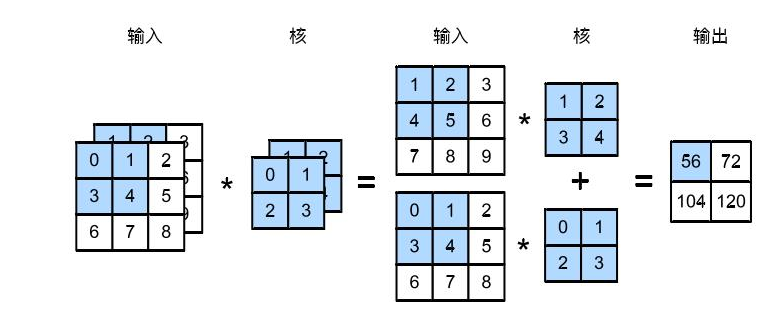
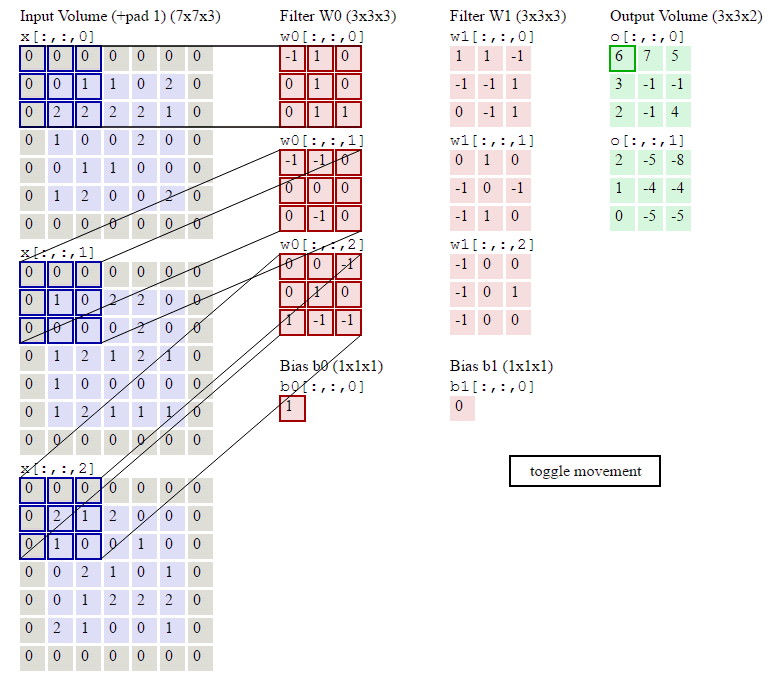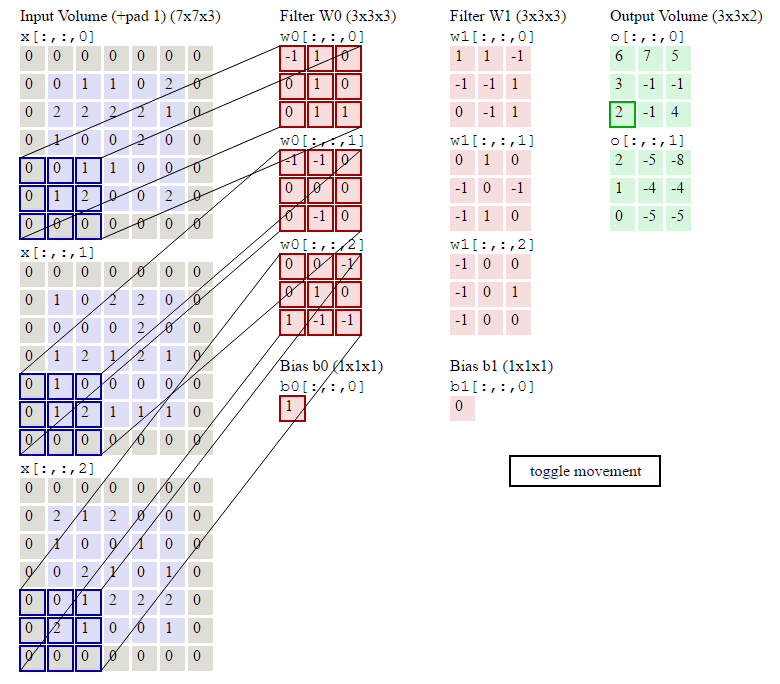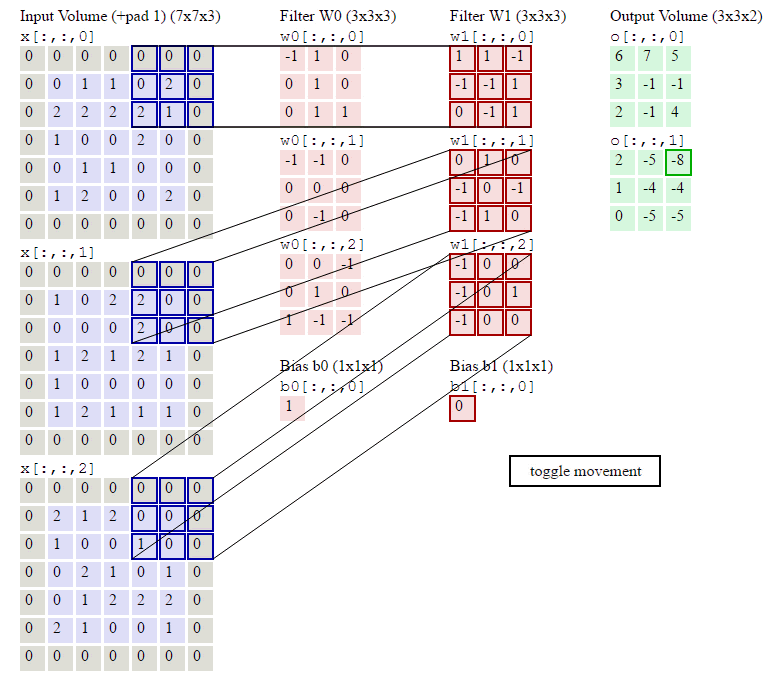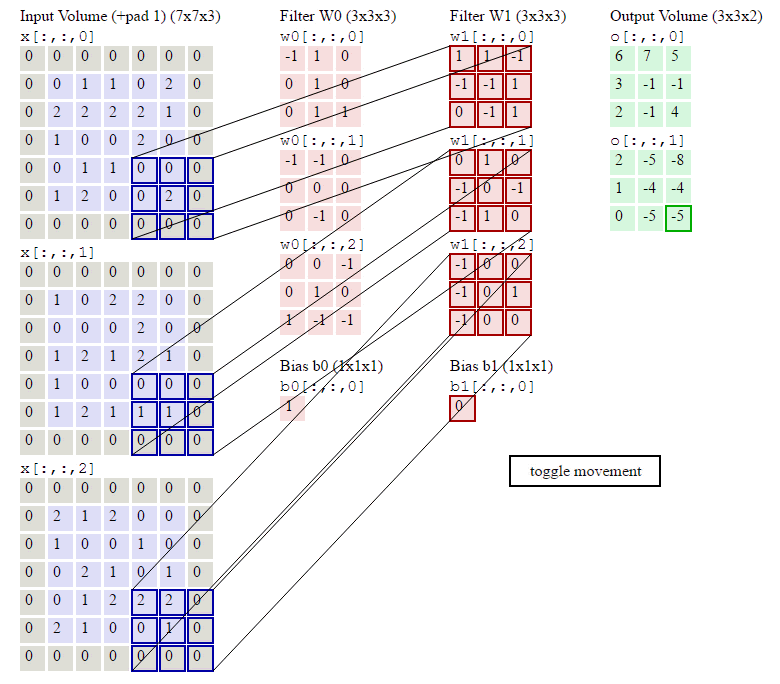
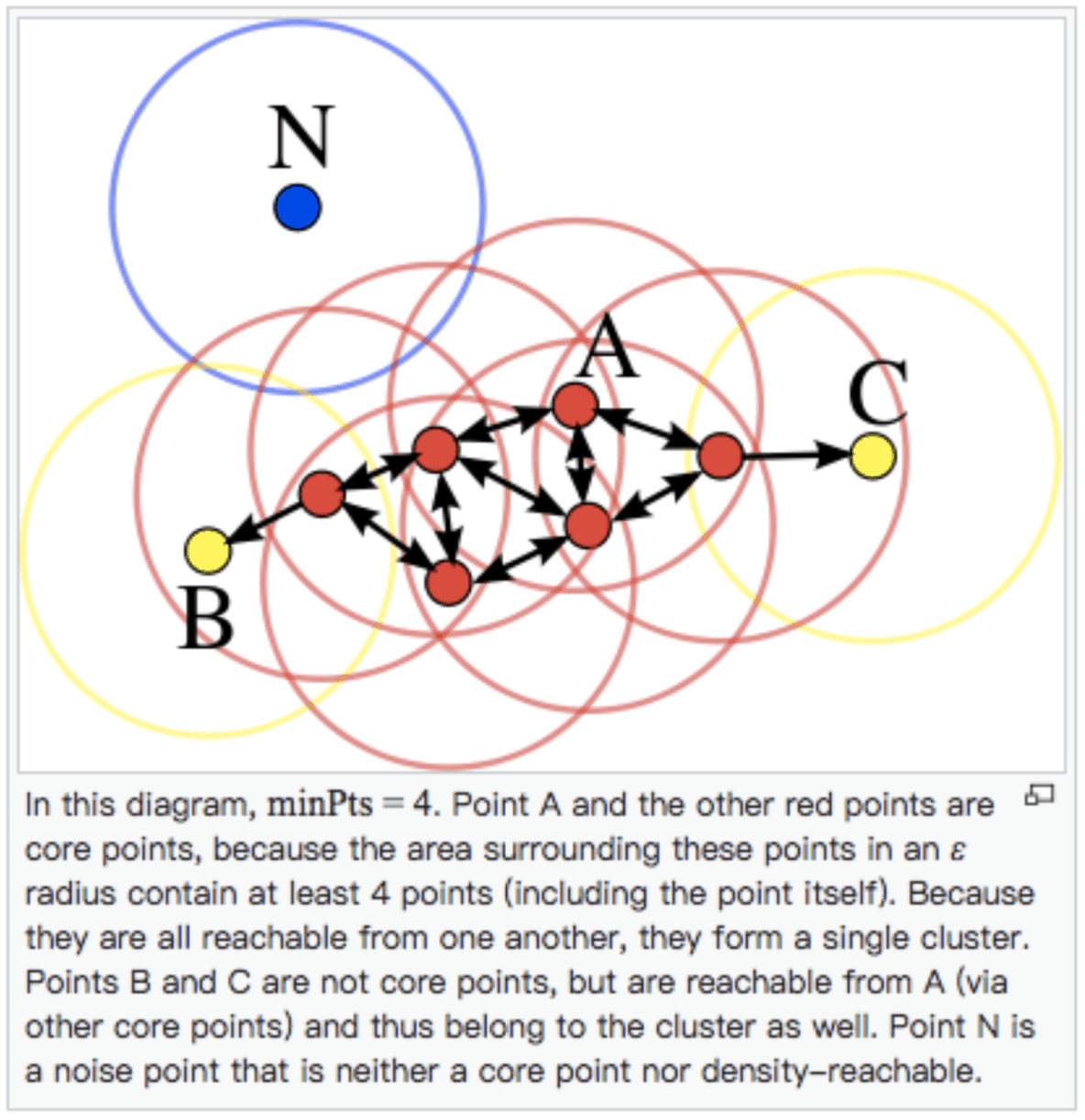
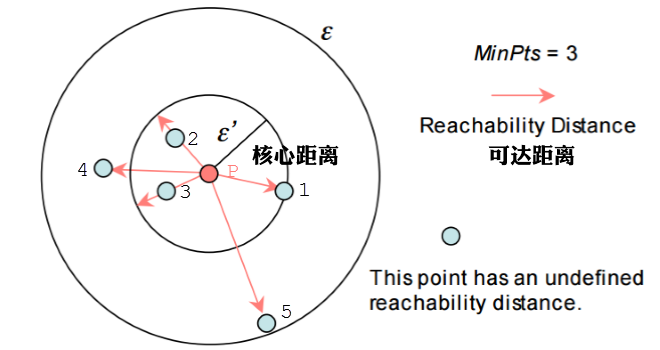
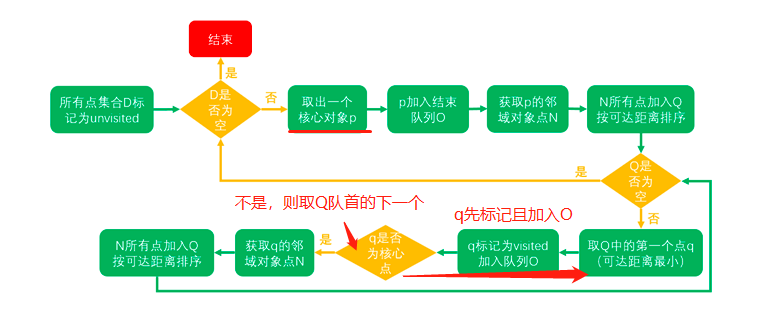
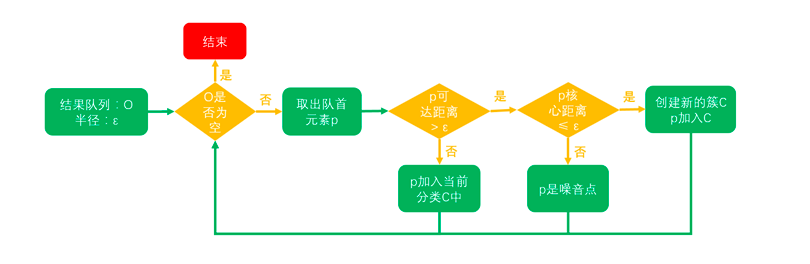
2019,被大多数温暖环绕,偶尔一些人生瞬间变得冰冷和坚硬,无法躲避。但还好,一切终将过去。总的来说,2019并不简单,生活频繁出拳(胖虎的300斤铁拳,直立对打,凭着经验和运气躲过一些,另外一些结结实实地砸在脸上。可以说每一拳都不含糊,一击重拳,甚至可以感受到在脸上凝固停滞的拳气。不过今年也算是和生活对过几招了,本想着步步清风认真生活,凭阅历自撰一本《人间攻略》,大摇大摆地走上建设社会的征途,没想到生活反手甩一本《人间骚浪贱指南》,害,2019全线崩溃,2020推倒重来,希望今年和生活再次交手能从容一些了。
「说真的,你将来打算怎么办呢?」「我打算喝完这一杯」
研究生毕业失与得
- 毕业
研究生三年,形象地说, 从一个小池塘跳到另外一个小池塘中,激起一朵Information Sciences期刊论文小浪花,然后扑通入水无踪影,从二十几岁精壮小伙想掏空世界的功利心来看,不值当。很难想象,这朵靠着身体抽搐翻腾出来小破花有多艰难,为啥别人的象牙塔是导师领进豪华直升电梯,直通塔顶,而我们要一步一爬,唉哟连特么象牙塔都是自己垒起来的,还好最后实验室人手一篇领域(次)顶刊,纷纷告别科研学术,有着不错的工作落脚处,也算是纯粹地感受了一把学术上知其然也知其所以然过程,人生历程多了一份体验,虽然不符预期,但也感激经历。
学校这几年忙忙忙,感觉也没忙出啥东西来,没发展别的兴趣,甜甜的恋爱还是没轮到我,好像蓝色大门里说的「 夏天就要过去了,我们好像什么都没做」「 是啊,就这样跑来跑去,什么都没做 」「那总会留下些什么吧,留下了什么,我们就会成为怎么样的大人 」
真要说有哪些值得关注的改变话,觉得还是有一些:
- 喜欢上了摇滚乐
- 性格从怂包变得小型社恐(到今天似乎消除了,大家都一样,五五开)
- 资源搜索能力加强,有需要的东西可以独立自学
- 处理感情还是一塌糊涂,不能成熟表达爱与索取爱
- 总在试探,都在权衡,消散热爱的能力
毕业的话,希望自己的期刊论文每年多一次引用吧,谷歌学术搜索排名能前一点,这个新年学术愿望不过分吧。
- 就业
面试造火箭,上班拧螺丝的故事早有耳闻,人力小姐姐萝莉外表杀人诛心可不含糊,论实力与面试的迷一样的相关函数,求职路上太多有意思的故事了,这一路也不容易。
忙着论文错过了秋招,磕磕碰碰地走上春招这条血路,太难了呀,简直比沥青未干的蜀道还难!一场场大型面试崩溃招聘现场, 黑压压一片学生,排着队递简历,精神上首先就完了。投了简历石沉大海,回来路上,真的是天空突然一道光打在你身上,自我怀疑的高光时刻。二十五岁这场人生三分之一考试,每次到交答卷才发现真的准备的不够充分。春招凭着发表的论文和一些算法竞赛的获奖,获得较多的面试机会,磕磕碰碰,沉舟侧畔,最后也算成功上岸了,有两个比较有印象的故事:
1)投了一些大厂算法类的岗位无果后,参加了一个猎头帮改简历的招聘会,那天去的早, 现场没啥人,改完简历后和猎头大叔聊了起来,咔咔咔一顿哭诉当代年轻人的不容易,委屈大王,心酸2019,为啥生活不如意都落我这个失意年轻人的大头上!(那段时间感情状态、生活状态各方面真的是DOWN到深海几万里)。猎头大叔当时说啥我忘记了,总之谈了很久,他让我加油坚持,不要放低要求去小企业得以慰藉,年轻人要有年轻人的样子!我心中一顿爆暖,离开的时候还喊了我回来,握了握手,说很开心和我谈话。
2)一家基金公司,总裁面,到了给offer阶段,我说还有另外一家在考虑,她说来不来她这里没关系,年轻人找工作要好好考虑,要选对行业和团队,不要盯着一个岗位就上,并给了很多中肯的年轻人意见。我是很信仰人生经验攻略的,这些年一路过来,可太缺参考物了,最后没去还是很谢谢这些不给年轻人画饼,并愿意指导年轻人意见的大佬。
给毕业求职的同学一些建议:
- 不要错过秋春招
- 清楚自己的满意和愿意接受的岗位
- 校招不像做饭,不需要等万事俱备才开始
- 每次多总结复盘,打铁还需自身硬
- 小心人力大姐
以上其实都是废话,多面几次自己就有谱了
不管怎样,还是顺利毕业了嘿!

自我管理
1.睡眠
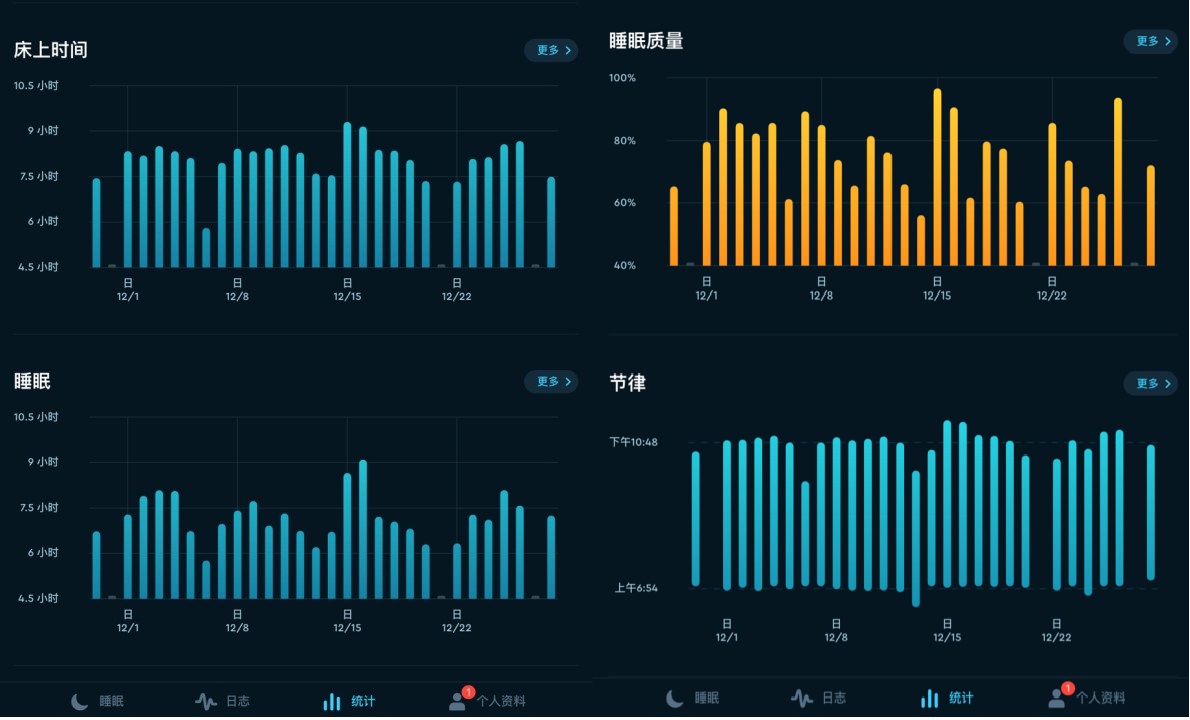
出来搬砖以来,睡眠变得规律很多,七点起床,十点半准时雇人敲晕自己。睡眠时间大概维持在七个半小时,午休半小时,持续搬砖问题不大。周末一般会把一周攒起来的抖音刷一遍,看看天地之间的沙雕,安心睡去。
- 记账
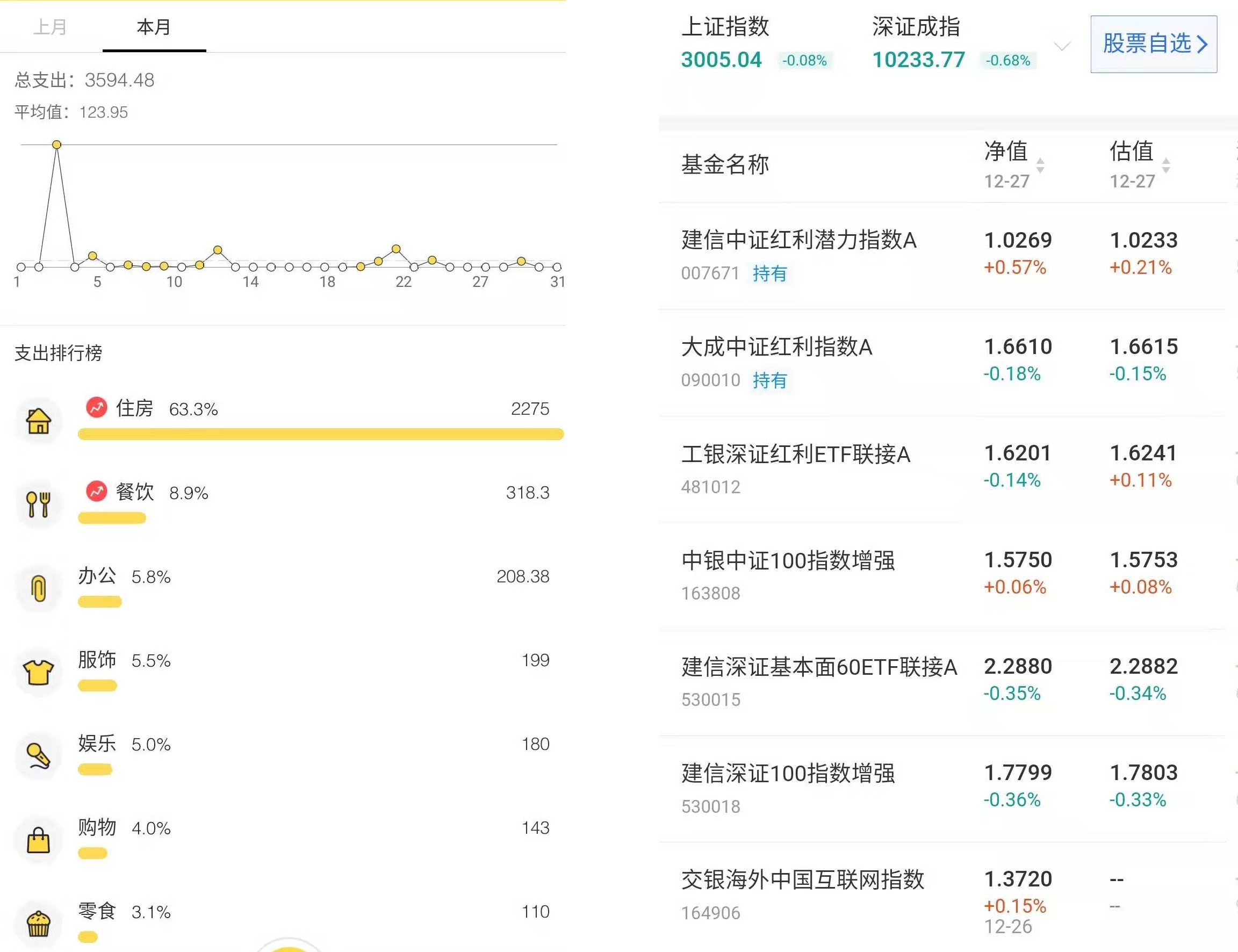
不得不说,当代年轻人独立买房还是很艰难,看着每项支出其实也还好,但是汇到一起每月支出都会比想象的多,要是活动多一些也存不了几个钱。今年出来搬砖后,把银行和朋友借的钱都还清,自己日常支出也能稳定下来,这个感觉还是很棒的!
定投指数基金,3000点入场,做一颗茁壮成长的韭菜!
- 健康
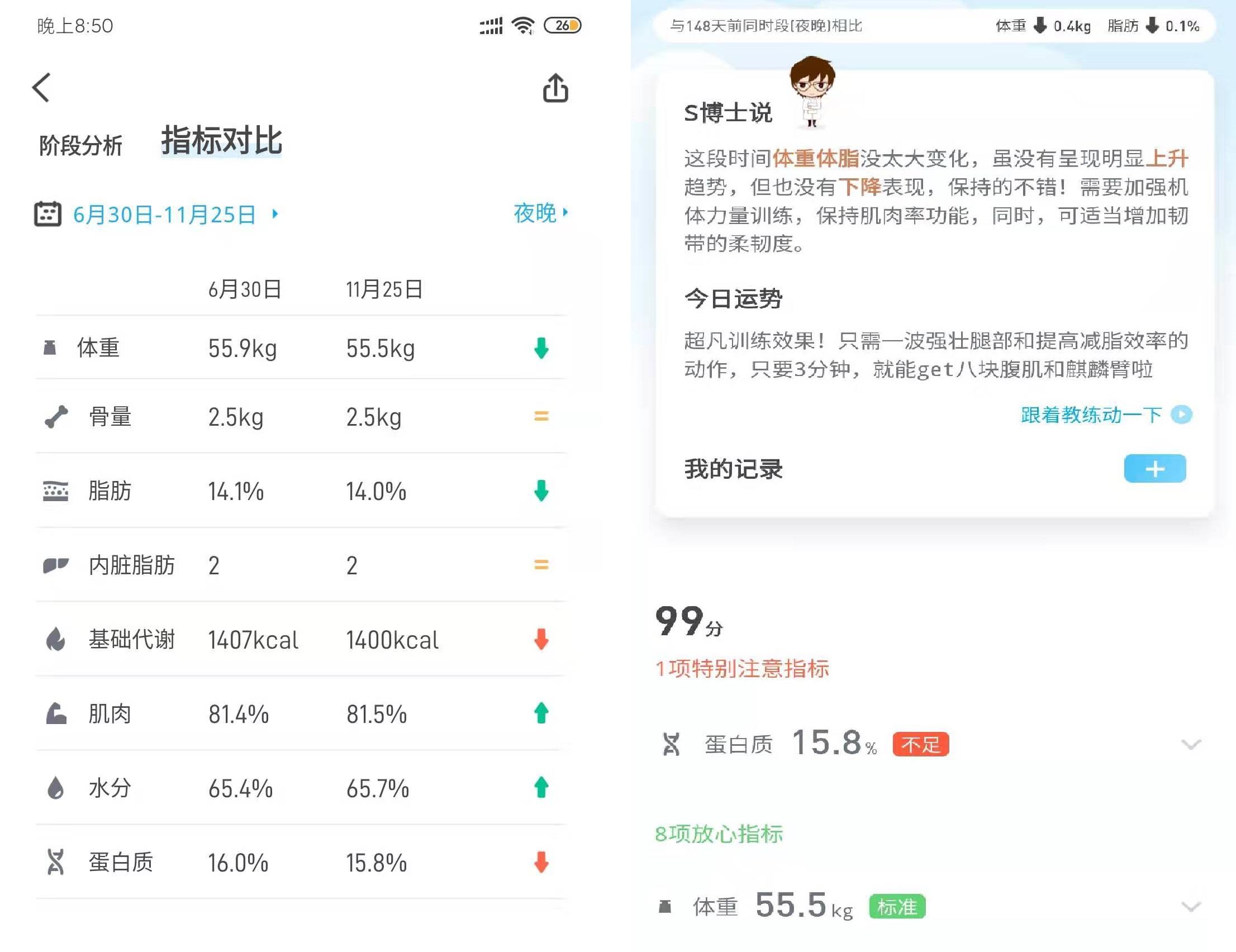
今年做了个手术,还确诊了过敏性鼻炎,是要提醒自己该更加注意身体健康这一方面了。另外鼻炎应该是学校宿舍那台旧空调造成的,风口对着床吹,还滴水,每次在宿舍鼻子难受的不行,去到实验室马上就好了,弄到这个不治的毛病还是很痛苦的。目前的策略是上班走路走路走路!枸杞枸杞枸杞!泡脚泡脚泡脚! 健身是没戏了,在学校都没能坚持下来,希望明年能坚持去游个泳吧。
关于书影音

五星电影:
- 极限职业(韩)
- 调音师(印度)
- 海蒂和爷爷(德)
- 复仇者联盟4(美)
- 摇摆狂潮(韩)
书籍:
- 《代码整洁之道—程序员的职业素养》
- 《代码整洁之道—Clean》
- 《黑客与画家》
- 《交换梦想》
- 《宇宙超度指南》
- 《如何成为一个厉害的人》
音乐演出
- 陈知游园惊梦 2019避雨屋檐巡演
- Brett乐队 2019巡演
- 文雀乐队 2019她从来不唱我们的歌巡演
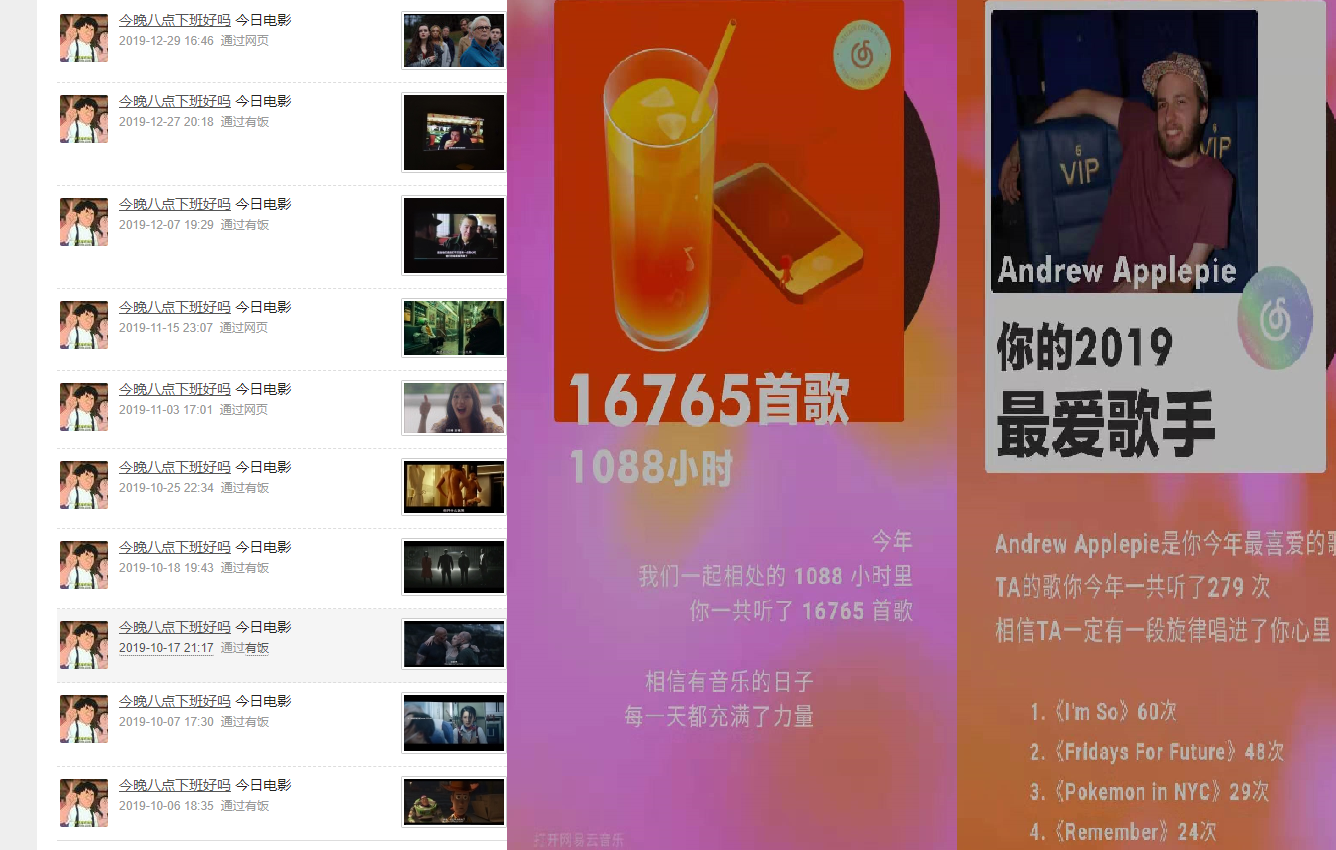
今年观影70+,还为观影事业买了个投影仪,每个周末的夜晚,100寸电子辐射的快乐,碳水化合物乐园,灵魂像膨化食品被打开时一样开心的裂开。听歌方面依然是摇滚为主,流行和民谣听一些,没想到居然Andrew Applepie成为了年度歌手,一度认为人类必须牵着手才能听Applepie,哎呀哎呀摇滚死了呀。
今年看书希望多看些编程类的工具书,数据库、理解框架是目前搬砖进阶的目标。
不要为今年读书太少而难过,去年你也没读多少
Flag!Flag!Flag!
希望今年可以更自信地表达自己
搬出来一个人住,养条狗,或养个女朋友
尝试视频内容创作
开源一个自己感兴趣的工程项目
逛一逛动物园,打卡深圳所有公园
存钱买老婆
总的来说,2019并不值得被总结,是经历当中最难的一年,有很多至暗时刻不愿提及,没必要铭记些什么,2019过去了就过去了。用一些不太恰当又很冗长的比喻就是, 就像聊了18个月的心理医生突然告诉你,我不能再给你做咨询了,因为我已经爱上你了; 就像一个易碎的老年人正盯着你并且缓缓插队,而你只好故作无睹 ;就像班上倒数第二辅导倒数第一课后习题,并且给出详细的解题思路 。2020不敢说万事顺利,希望新一年遇到的问题都是不太复杂自己慢慢能处理好的,新年加油!
新的一年,就不祝一帆风顺了,祝大家乘风破浪吧!
以上