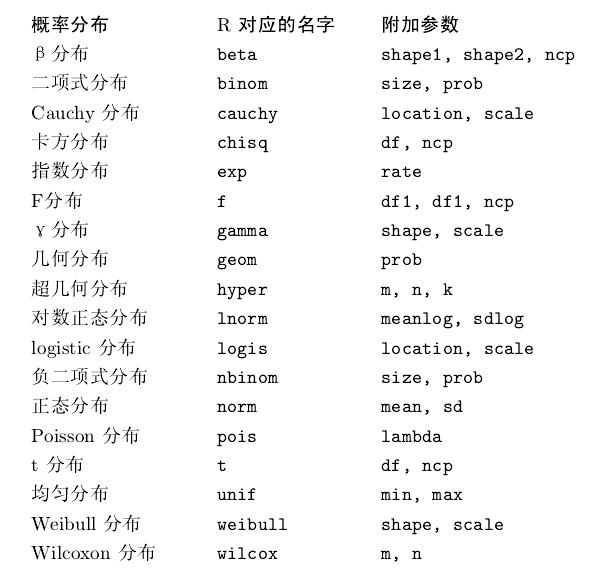
R 的统计表
不同的名字前缀表示不同的含义,d表示概率密度函数,p 表示累积分布函数(cumulative distribution function,CDF),q 表示分位函数以及r 表示随机模拟(random deviates)或者随机数发生器
1 | 我们可以用很多方法分析一个单变量数据集的分布。最简单的办法就是直接看数字。利用函数summary 和fivenum 会得到两个稍稍有点差异的汇总信息。 此外,stem(“茎叶”图)也会反映整个数据集的数字信息。用函数hist 绘制柱状图。 |
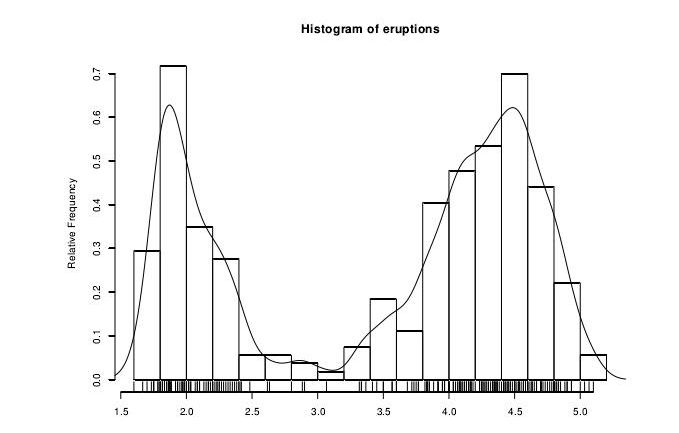
函数ecdf 绘制一个数据集的经验累积分布(empirical cumulativedistribution)函数。
分位比较图(Quantile-quantile (Q-Q) plot),又称QQ图,通常用于检验是否满足正态分布
1 | # 检验是否符合正态分布 |
1 | 利用Shapiro-Wilk方法进行正态检验 |
1 | 到现在为止,我们已经学会了单样本的正态性检验。而更常见的操作是比较两个样本的特征。在R 里面,所有“传统”的检验都放在包stats 里面。这个包常常会自动载入。 |
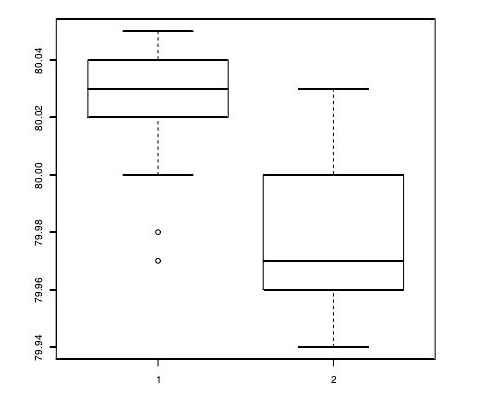
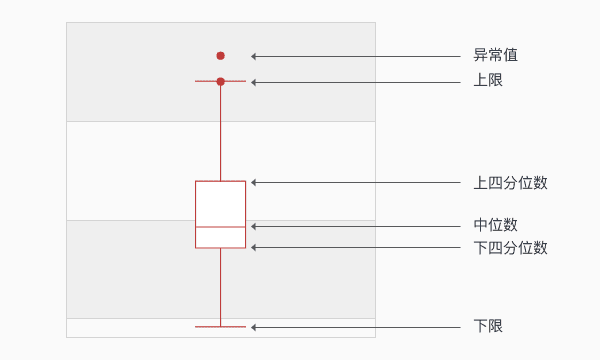
简单来说,通过把所得到的统计检定值与统计学家建立了一些随机变量的概率分布进行比较,证明样本的统计结果不是随机得到的,是有意义的。专业上,P值或sig值为结果可信程度的一个递减指标,如p=0.05提示样本中变量关联有5%的可能是由于偶然性造成的。即假设总体中任意变量间均无关联。
1 | R 语言的条件语句形式为 |