写在前面:这个系列打算把「Hands-On Machine Learning with Scikit-Learn and TensorFlow 」重新梳理一遍,这本书在看完机器学习基础知识之后有一个很好的算法实践,对于算法落地有很多帮助。这次写的Sklearn 与 TensorFlow 机器学习实用指南系列,目的是让自己更清楚算法的每个流程处理,加强对一些机器学习模型理解。这本书在github有中文的翻译版本(还在更新).
拆分数据集
训练集+测试集
1 | import numpy as np |
或者直接将整体数据打乱,然后按需取量。(california_housing_dataframe为谷歌机器学习教程提供的加州住房数据)
1 | california_housing_dataframe = california_housing_dataframe.reindex( # 整体打乱 |
以上为训练集+测试集的拆分方式
训练集+验证集+测试集
这样的拆分方式主要有存在一些不足。1、程序多次运行后,测试集的数据有可能会加入到训练集当中,调参时用于改进模型超参数的测试集会造成过拟合。2、不便于新数据的加入
更好的办法是将数据集拆分为训练集+验证集+测试集。
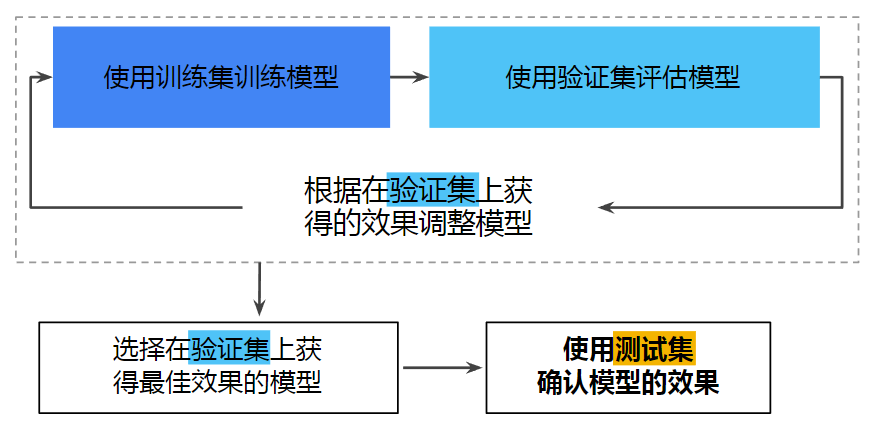
那如何解决新加入数据的问题呢?一个通常的解决办法是使用每个实例的识别码,以判定是否这个实例是否应该放入测试集(假设实例有单一且不变的识别码)。例如,你可以计算出每个实例识别码的哈希值,只保留其最后一个字节,如果值小于等于 51(约为 256 的 20%),就将其放入测试集。这样可以保证在多次运行中,测试集保持不变,即使更新了数据集。新的测试集会包含新实例中的 20%,但不会有之前位于训练集的实例。可能很多数据没有稳定的特征,最简单的办法就是利用索引作为识别码。下面的代码根据识别码按0.7,0.2,0.1比例拆分训练集、验证集和测试集。
1 | # 参数identifier为单一且不变的识别码,可以为索引id |
分成采样
另外一种拆分方式:分成采样
将人群分成均匀的子分组,称为分层,从每个分层去除合适数量的实例,以保证测试集对总人数有代表性。例如,美国人口的 51.3% 是女性,48.7% 是男性。所以在美国,严谨的调查需要保证样本也是这个比例:513 名女性,487 名男性作为数据样本。数据集中的每个分层都要有足够的实例位于你的数据中,这点很重要。否则,对分层重要性的评估就会有偏差。这意味着,你不能有过多的分层,且每个分层都要足够大。后面的代码通过将收入中位数除以 1.5(以限制收入分类的数量),创建了一个收入类别属性,用ceil对值舍入(以产生离散的分类),然后将所有大于 5的分类归入到分类5 :
1 | # 预处理,创建"income_cat"属性 |
数据预处理
将原始数据映射到特征
我们在进行机器学习的时候,采用的数据样本往往是矢量(特征矢量),而我们的原始数据并不是以矢量的形式呈现给我们的,这是便需要将数据映射到特征
整数和浮点数映射
直接映射便ok(虽然机器学习是根据浮点值进行的训练,但是不需要将整数6转换为6.0,这个过程是默认的)
字符串映射
好多时候,有的特征是字符串,比如此前训练的加利福尼亚房产数据集中的街区名称,机器学习是无法根据字符串来学习规律的,所以需要转换。但是存在一个问题,如果字符特征是’’一环’’ ‘’二环’’ ‘’三环’’…(代表某个城市的地理位置),那么对其进行数值转换的时候,是不可以编码为形如1,2,3,4…这样的数据的,因为其存在数据大小的问题,学习模型会把他们的大小关系作为特征而学习,所以我们需要引入独热编码,(具体解释见链接,解释的很好).我们需要把这些文本标签转换为数字。Scikit-Learn 为这个任务提供了一个转换器LabelEncoder:
1 | # 简单来说 LabelEncoder 是对不连续的数字或者文本进行编号 |
译注:
在原书中使用
LabelEncoder转换器来转换文本特征列的方式是错误的,该转换器只能用来转换标签(正如其名)。在这里使用LabelEncoder没有出错的原因是该数据只有一列文本特征值,在有多个文本特征列的时候就会出错。应使用factorize()方法来进行操作:
2
housing_cat_encoded[:10]
处理离散特征这还不够,Scikit-Learn 提供了一个编码器OneHotEncoder,用于将整书分类值转变为独热向量。注意fit_transform()用于 2D 数组,而housing_cat_encoded是一个 1D 数组,所以需要将其变形:
1 | # reshape(-1,1)里面的-1代表将数据自动计算有多少行,但是列数明确设置为1 |
注意输出结果是一个 SciPy 稀疏矩阵,而不是 NumPy 数组。当类别属性有数千个分类时,这样非常有用。经过独热编码,我们得到了一个有数千列的矩阵,这个矩阵每行只有一个 1,其余都是 0。使用大量内存来存储这些 0 非常浪费,所以稀疏矩阵只存储非零元素的位置。你可以像一个 2D 数据那样进行使用,但是如果你真的想将其转变成一个(密集的)NumPy 数组,只需调用toarray()方法:
1 | housing_cat_1hot.toarray() |
使用类LabelBinarizer,我们可以用一步执行这两个转换(从文本分类到整数分类,再从整数分类到独热向量):
1 | from sklearn.preprocessing import LabelBinarizer |
注意默认返回的结果是一个密集 NumPy 数组。向构造器LabelBinarizer传递sparse_output=True,就可以得到一个稀疏矩阵。
译注:
在原书中使用
LabelBinarizer的方式也是错误的,该类也应用于标签列的转换。正确做法是使用sklearn即将提供的CategoricalEncoder类。如果在你阅读此文时sklearn中尚未提供此类,用如下方式代替:(来自Pull Request #9151)
2
3
4
5
6
cat_encoder = CategoricalEncoder()
housing_cat_reshaped = housing_cat.values.reshape(-1, 1)
housing_cat_1hot = cat_encoder.fit_transform(housing_cat_reshaped)
housing_cat_1hot
寻找良好特征(的特点)
当得到特征之后,还是要进行筛选的,因为有的特征没有参考价值,就像我们的在做合成特征的时候,正常的特征数据是人均几间房间,而有的人是几十间,这明显没有参考价值
良好特征的几点原则
避免很少使用的离散特征值:如果只是出现了一两次的特征几乎是没有意义的
最好具有清晰明确的含义:特征的含义不仅仅是让机器学习的模型学习的,人也要知道其具体的含义,不然不利于分析数据(最好将数值很大的秒转换为天数,或者年,让人看起来直观一些)
将“神奇”的值与实际数据混为一谈:有些特征中会出现一些”神奇的数据”,当然这些数据并不是很少的特征,而是超出范围的异常值,比如特征应该是介于0——1之间的,但是因为这个数据是空缺的,而采用的默认数值-1,那么这样的数值就是”神奇”,解决办法是,将该特征转换为两个特征:
- 一个特征只存储质正常范围的值,不含神奇值。
- 一个特征存储布尔值,表示的信息为是否为空
考虑上游不稳定性:由经验可知,特征的定义不应随时间发生变化,代表城市名称的话,那么特征值始终都该是城市的名称,但是有的时候,上游模型将特征值处理完毕后,返还给下游模型的却变成了数值,这样是不好的,因为这种表示在未来运行其他模型时可能轻易发生变化,那么特征就乱套了
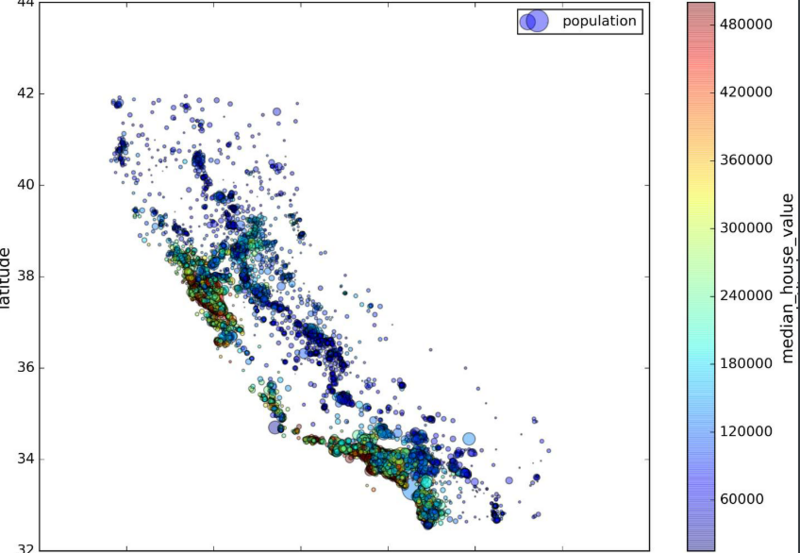
可视化数据寻找规律:
1 | housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4, |
每个圈的半径表示街区的人口(选项s),颜色代表价格(选项c)。我们用预先定义的名为jet的颜色图(选项cmap),它的范围是从蓝色(低价)到红色(高价):
皮尔逊相关系数
1 | corr_matrix = housing.corr() |
Pandas 的scatter_matrix函数
另一种检测属性间相关系数的方法是使用 Pandas 的scatter_matrix函数,它能画出每个数值属性对每个其它数值属性的图。因为现在共有 11 个数值属性,你可以得到11 ** 2 = 121张图。
1 | from pandas.tools.plotting import scatter_matrix |
得到两个属性的散点图

清查数据
截至目前,我们假定用于训练和测试的所有数据都是值得信赖的。在现实生活中,数据集中的很多样本是不可靠的,原因有以下一种或多种:
- 遗漏值。 例如,有人忘记为某个房屋的年龄输入值。(值会为-1,所以要分为两个特征,忘了的看上面)
- 重复样本。 例如,服务器错误地将同一条记录上传了两次。
- 不良标签。 例如,有人错误地将一颗橡树的图片标记为枫树。
- 不良特征值。 例如,有人输入了多余的位数,或者温度计被遗落在太阳底下。
一旦检测到存在这些问题,通常需要将相应样本从数据集中移除,从而“修正”不良样本。要检测遗漏值或重复样本,可以编写一个简单的程序。检测不良特征值或标签可能会比较棘手,可采用可视化数据的方法。
对于处理特征丢失的问题。前面,你应该注意到了属性total_bedrooms有一些缺失值。有三个解决选项:
- 去掉对应的街区;(数据大可用)
- 去掉整个属性;
- 进行赋值(0、平均值、中位数等等)。
用DataFrame的dropna(),drop(),和fillna()方法,可以方便地实现:
1 | housing.dropna(subset=["total_bedrooms"]) # 选项1 |
如果选择选项 3,你需要计算训练集的中位数,用中位数填充训练集的缺失值,不要忘记保存该中位数。后面用测试集评估系统时,需要替换测试集中的缺失值,也可以用来实时替换新数据中的缺失值。
Scikit-Learn 提供了一个方便的类来处理缺失值:Imputer。下面是其使用方法:首先,需要创建一个Imputer实例,指定用该属性的中位数替换它的每个缺失值:
1 | from sklearn.preprocessing import Imputer |
因为只有数值属性才能算出中位数,我们需要创建一份不包括文本属性ocean_proximity的数据副本:
1 | housing_num = housing.drop("ocean_proximity", axis=1) # 去除ocean_proximity不为数值属性的特征 |
现在,就可以用fit()方法将imputer实例拟合到训练数据:
1 | imputer.fit(housing_num) |
imputer计算出了每个属性的中位数,并将结果保存在了实例变量statistics_中。只有属性total_bedrooms有缺失值,但是我们确保一旦系统运行起来,新的数据中没有缺失值,所以安全的做法是将imputer应用到每个数值:
1 | imputer.statistics_ # 实例变量statistics_和housing_num数值数据得到的中位数是一样的 |
现在,你就可以使用这个“训练过的”imputer来对训练集进行转换,通过将缺失值替换为中位数:
1 | X = imputer.transform(housing_num) |
结果是一个普通的 Numpy 数组,包含有转换后的特征。如果你想将其放回到 PandasDataFrame中,也很简单:
1 | housing_tr = pd.DataFrame(X, columns=housing_num.columns) # 得到处理缺失值后的DF数据 |
整理数据:
数据缩放
有两种常见的方法可以让所有的属性有相同的量度:线性函数归一化(Min-Max scaling)和标准化(standardization)。Scikit-Learn 提供了一个转换器MinMaxScaler来实现这个功能。它有一个超参数feature_range,可以让你改变范围,如果不希望范围是 0 到 1;Scikit-Learn 提供了一个转换器StandardScaler来进行标准化
min-max方式,对应的方法为
1 | MinMaxScaler(self, feature_range=(0, 1), copy=True) |
standardization 标准化数据,对应的方法为
1 | StandardScaler(self, copy=True, with_mean=True, with_std=True) |
警告:与所有的转换一样,缩放器只能向训练集拟合,而不是向完整的数据集(包括测试集)。只有这样,你才能用缩放器转换训练集和测试集(和新数据)。
处理极端离群值
还是举加利福尼亚州住房数据集中的人均住房数的例子,有的极端值达到了50
对于这些极端值其实很好处理,无非几个办法
- 对数缩放
1 | roomsPerPerson = log((totalRooms / population) + 1) |
- 特征值限制到 某个上限或者下限
1 | roomsPerPerson = min(totalRooms / population, 4) # 大于4.0的取4.0 |
分箱
分箱其实是一个形象化的说法,就是把数据分开来,装在一个个箱子里,这样一个箱子里的数据就是一家人了。
那有什么用呢?下面就举个栗子!
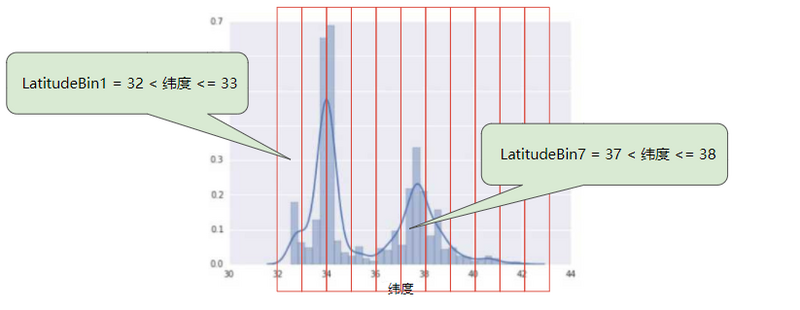
在数据集中,latitude 是一个浮点值。不过,在我们的模型中将 latitude 表示为浮点特征没有意义。这是因为纬度和房屋价值之间不存在线性关系。例如,纬度 35 处的房屋并不比纬度 34 处的房屋贵 35/34(或更便宜)。但是,纬度或许能很好地预测房屋价值。
我们现在拥有 11 个不同的布尔值特征(LatitudeBin1、LatitudeBin2、…、LatitudeBin11),而不是一个浮点特征。拥有 11 个不同的特征有点不方便,因此我们将它们统一成一个 11 元素矢量。这样做之后,我们可以将纬度 37.4 表示为:
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
分箱之后,我们的模型现在可以为每个纬度学习完全不同的权重。(是不是觉得有点像独热编码,没错,就是的)
为了简单起见,我们在纬度样本中使用整数作为分箱边界。如果我们需要更精细的解决方案,我们可以每隔 1/10 个纬度拆分一次分箱边界。添加更多箱可让模型从纬度 37.4 处学习和维度 37.5 处不一样的行为,但前提是每 1/10 个纬度均有充足的样本可供学习。
另一种方法是按分位数分箱,这种方法可以确保每个桶内的样本数量是相等的。按分位数分箱完全无需担心离群值。
1 | ''' |
自定义转换器
尽管 Scikit-Learn 提供了许多有用的转换器,你还是需要自己动手写转换器执行任务,比如自定义的清理操作,或属性组合。你需要让自制的转换器与 Scikit-Learn 组件(比如流水线)无缝衔接工作,因为 Scikit-Learn 是依赖鸭子类型的(而不是继承,忽略对象,只要行为像就行),你所需要做的是创建一个类并执行三个方法:fit()(返回self),transform(),和fit_transform()。通过添加TransformerMixin作为基类,可以很容易地得到最后一个。另外,如果你添加BaseEstimator作为基类(且构造器中避免使用args和kargs),你就能得到两个额外的方法(get_params()和set_params()),二者可以方便地进行超参数自动微调。例如,一个小转换器类添加了上面讨论的属性:
1 | # 添加一个特征组合的装换器 |
在这个例子中,转换器有一个超参数add_bedrooms_per_room,默认设为True(提供一个合理的默认值很有帮助)。这个超参数可以让你方便地发现添加了这个属性是否对机器学习算法有帮助。更一般地,你可以为每个不能完全确保的数据准备步骤添加一个超参数。数据准备步骤越自动化,可以自动化的操作组合就越多,越容易发现更好用的组合(并能节省大量时间)。
另外sklearn是不能直接处理DataFrames的,那么我们需要自定义一个处理的方法将之转化为numpy类型
1 | class DataFrameSelector(BaseEstimator,TransformerMixin): |
转换流水线
目前在数据预处理阶段,我们需要对缺失值进行处理、特征组合和特征缩放。每一步的执行都有着先后顺序,存在许多数据转换步骤,需要按一定的顺序执行。sklearn提供了Pipeline帮助顺序完成转换幸运的是,Scikit-Learn 提供了类Pipeline,来进行这一系列的转换。下面是一个数值属性的小流水线:
1 | from sklearn.pipeline import Pipeline |
Pipeline构造器需要一个定义步骤顺序的名字/估计器对的列表。除了最后一个估计器,其余都要是转换器(即,它们都要有fit_transform()方法)。名字可以随意起。
当你调用流水线的fit()方法,就会对所有转换器顺序调用fit_transform()方法,将每次调用的输出作为参数传递给下一个调用,一直到最后一个估计器,它只执行fit()方法。
估计器(Estimator):很多时候可以直接理解成分类器,主要包含两个函数:fit()和predict()
转换器(Transformer):转换器用于数据预处理和数据转换,主要是三个方法:fit(),transform()和fit_transform()
最后的估计器是一个StandardScaler,它是一个转换器,因此这个流水线有一个transform()方法,可以顺序对数据做所有转换(它还有一个fit_transform方法可以使用,就不必先调用fit()再进行transform())。
1 | num_attribs = list(housing_num) # 返回的为列名[col1,col2,....] |
上面定义的为分别处理数值类型和标签类型的转换流程,housing_num为DataFrame类型,list(DataFrame)的结果返回的为列名字。上面着两个流程还可以再整合一起。
1 | from sklearn.pipeline import FeatureUnion |
译注:
如果你在上面代码中的
cat_pipeline流水线使用LabelBinarizer转换器会导致执行错误,解决方案是用上文提到的CategoricalEncoder转换器来代替:
2
3
4
('selector', DataFrameSelector(cat_attribs)),
('cat_encoder', CategoricalEncoder(encoding="onehot-dense")),
])
每个子流水线都以一个选择转换器开始:通过选择对应的属性(数值或分类)、丢弃其它的,来转换数据,并将输出DataFrame转变成一个 NumPy 数组。Scikit-Learn 没有工具来处理 PandasDataFrame,因此我们需要写一个简单的自定义转换器来做这项工作:
1 | from sklearn.base import BaseEstimator, TransformerMixin |
训练模型
我们先来训练一个线性回归模型:
1 | from sklearn.linear_model import LinearRegression |
完毕!你现在就有了一个可用的线性回归模型。用一些训练集中的实例做下验证:
1 | some_data = housing.iloc[:5] # 前五个作为预测数据 |
行的通,尽管预测并不怎么准确(比如,第二个预测偏离了 50%!)。让我们使用 Scikit-Learn 的mean_squared_error函数,用全部训练集来计算下这个回归模型的 RMSE:
1 | from sklearn.metrics import mean_squared_error |
OK,有总比没有强,但显然结果并不好,这是一个模型欠拟合训练数据的例子。当这种情况发生时,意味着特征没有提供足够多的信息来做出一个好的预测,或者模型并不强大,修复欠拟合的主要方法是选择一个更强大的模型,给训练算法提供更好的特征,或去掉模型上的限制,你可以尝试添加更多特征(比如,人口的对数值),但是首先让我们尝试一个更为复杂的模型,看看效果。训练一个决策树模型DecisionTreeRegressor。这是一个强大的模型,可以发现数据中复杂的非线性关系。
1 | from sklearn.tree import DecisionTreeRegressor |
等一下,发生了什么?没有误差?这个模型可能是绝对完美的吗?当然,更大可能性是这个模型严重过拟合数据。如何确定呢?如前所述,直到你准备运行一个具备足够信心的模型,都不要碰测试集,因此你需要使用训练集的部分数据来做训练,用一部分来做模型验证。
用交叉验证做更佳的评估
使用 Scikit-Learn 的交叉验证功能。下面的代码采用了 K 折交叉验证(K-fold cross-validation):它随机地将训练集分成十个不同的子集,成为“折”,然后训练评估决策树模型 10 次,每次选一个不用的折来做评估,用其它 9 个来做训练。结果是一个包含 10 个评分的数组:
1 | from sklearn.model_selection import cross_val_score |
警告:Scikit-Learn 交叉验证功能期望的是效用函数(越大越好)而不是损失函数(越低越好),因此得分函数实际上与 MSE 相反(即负值),这就是为什么前面的代码在计算平方根之前先计算-scores。
来看下结果
1 | def display_scores(scores): |
现在决策树就不像前面看起来那么好了。实际上,它看起来比线性回归模型还糟!注意到交叉验证不仅可以让你得到模型性能的评估,还能测量评估的准确性(即,它的标准差)。决策树的评分大约是 71200,通常波动有 ±3200。如果只有一个验证集,就得不到这些信息。但是交叉验证的代价是训练了模型多次,不可能总是这样。
让我们计算下线性回归模型的的相同分数,以做确保:
1 | lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels, |
判断没错:决策树模型过拟合很严重,它的性能比线性回归模型还差
现在再尝试最后一个模型:RandomForestRegressor(随机森林),随机森林是通过用特征的随机子集训练许多决策树。在其它多个模型之上建立模型成为集成学习(Ensemble Learning),它是推进 ML 算法的一种好方法。我们会跳过大部分的代码,因为代码本质上和其它模型一样:
1 | from sklearn.ensemble import RandomForestRegressor |
现在好多了:随机森林看起来很有希望。但是,训练集的评分仍然比验证集的评分低很多。解决过拟合可以通过简化模型,给模型加限制(即,正则化),或用更多的训练数据。在深入随机森林之前,你应该尝试下机器学习算法的其它类型模型(不同核心的支持向量机,神经网络,等等),不要在调节超参数上花费太多时间。目标是列出一个可能模型的列表(两到五个)。
提示:你要保存每个试验过的模型,以便后续可以再用。要确保有超参数和训练参数,以及交叉验证评分,和实际的预测值。这可以让你比较不同类型模型的评分,还可以比较误差种类。你可以用 Python 的模块pickle,非常方便地保存 Scikit-Learn 模型,或使用sklearn.externals.joblib,后者序列化大 NumPy 数组更有效率:
1 | from sklearn.externals import joblib |
模型微调
网格搜索:使用 Scikit-Learn 的GridSearchCV来做这项搜索工作。你所需要做的是告诉GridSearchCV要试验有哪些超参数,要试验什么值,GridSearchCV就能用交叉验证试验所有可能超参数值的组合。例如,下面的代码搜索了RandomForestRegressor超参数值的最佳组合(很费时间):
1 | from sklearn.model_selection import GridSearchCV |
当你不能确定超参数该有什么值,一个简单的方法是尝试连续的 10 的幂(如果想要一个粒度更小的搜寻,可以用更小的数,就像在这个例子中对超参数n_estimators做的)。
param_grid告诉 Scikit-Learn 首先评估所有的列在第一个dict中的n_estimators和max_features的3 × 4 = 12种组合(不用担心这些超参数的含义,会在第 7 章中解释)。然后尝试第二个dict中超参数的2 × 3 = 6种组合,这次会将超参数bootstrap设为False而不是True(后者是该超参数的默认值)。完成后,你就能获得参数的最佳组合,如下所示:
1 | grid_search.best_params_ |
你还能直接得到最佳的估计器:
1 | grid_search.best_estimator_ |
当然,也可以得到评估得分:
1 | cvres = grid_search.cv_results_ |
在这个例子中,我们通过设定超参数max_features为 6,n_estimators为 30,得到了最佳方案。对这个组合,RMSE 的值是 49959,这比之前使用默认的超参数的值(52634)要稍微好一些。祝贺你,你成功地微调了最佳模型!
随机搜索:当探索相对较少的组合时,就像前面的例子,网格搜索还可以。但是当超参数的搜索空间很大时,最好使用RandomizedSearchCV。这个类的使用方法和类GridSearchCV很相似,但它不是尝试所有可能的组合,而是通过选择每个超参数的一个随机值的特定数量的随机组合。这个方法有两个优点:
- 如果你让随机搜索运行,比如 1000 次,它会探索每个超参数的 1000 个不同的值(而不是像网格搜索那样,只搜索每个超参数的几个值)
- 你可以方便地通过设定搜索次数,控制超参数搜索的计算量。
分析最佳模型和它们的误差
通过分析最佳模型,常常可以获得对问题更深的了解。比如,RandomForestRegressor可以指出每个属性对于做出准确预测的相对重要性:
1 | >>> feature_importances = grid_search.best_estimator_.feature_importances_ |
将重要性分数和属性名放到一起:
1 | extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"] |
有了这个信息,你就可以丢弃一些不那么重要的特征(比如,显然只要一个分类ocean_proximity就够了,所以可以丢弃掉其它的)。你还应该看一下系统犯的误差,搞清为什么会有些误差,以及如何改正问题(添加更多的特征,或相反,去掉没有什么信息的特征,清洗异常值等等)。
模型评估
调节完系统之后,你终于有了一个性能足够好的系统。现在就可以用测试集评估最后的模型了。这个过程没有什么特殊的:从测试集得到预测值和标签,运行full_pipeline转换数据(调用transform(),而不是fit_transform()!),再用测试集评估最终模型:
1 | final_model = grid_search.best_estimator_ |
评估结果通常要比交叉验证的效果差一点,如果你之前做过很多超参数微调(因为你的系统在验证集上微调,得到了不错的性能,通常不会在未知的数据集上有同样好的效果)。这个例子不属于这种情况,但是当发生这种情况时,你一定要忍住不要调节超参数,使测试集的效果变好;这样的提升不能推广到新数据上。