MNIST:手写数字分类数据集
1 | from sklearn.datasets import fetch_mldata |
MNIST 有 70000 张图片,每张图片有 784 个特征。这是因为每个图片都是28×28像素的,并且每个像素的值介于 0~255 之间。让我们看一看数据集的某一个数字。你只需要将某个实例的特征向量,reshape为28*28的数组,然后使用 Matplotlib 的imshow函数展示出来
1 | %matplotlib inline |

MNIST 数据集已经事先被分成了一个训练集(前 6000 张图片)和一个测试集(最后 10000 张图片)
1 | X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] |
打乱数据
1 | import numpy as np |
训练一个二分类器
现在我们简化一下问题,只尝试去识别一个数字,比如说,数字 5。这个“数字 5 检测器”就是一个二分类器,能够识别两类别,“是 5”和“非 5”。让我们为这个分类任务创建目标向量:
1 | # 在训练和测试集上区分是否为5转为0,1标签矩阵 |
采用随机梯度下降分类器
1 | from sklearn.linear_model import SGDClassifier |
输出预测结果
1 | sgd_clf.predict([some_digit]) |
分类器猜测这个数字代表 5(True)。看起来在这个例子当中,它猜对了。现在让我们评估这个模型的性能。
使用交叉验证测量准确性
评估一个模型的好方法是使用交叉验证,像之前提过一样。但有时为了有更好的控制权,可以写自己版本的交叉验证,以下代码粗略地做了和cross_val_score()相同的事情,并且输出相同的结果。
1 | from sklearn.model_selection import StratifiedKFold |
StratifiedKFold类实现了分层采样,生成的折(fold)包含了各类相应比例的样例。在每一次迭代,上述代码生成分类器的一个克隆版本,在训练折(training folds)的克隆版本上进行训,在测试折(test folds)上进行预测。然后它计算出被正确预测的数目和输出正确预测的比例。
这里使用sklearn提供的cross_val_score()函数来评估SGDClassifier模型
1 | from sklearn.model_selection import cross_val_score |
有大于 95% 的精度(accuracy),特别高!但要注意这是一个有数据偏差的数据集,这是因为只有 10% 的图片是数字 5,所以你总是猜测某张图片不是 5,你也会有90%的可能性是对的。处理这类问题,要回归到之前讲的准确率和召回率和ORC曲线了。
混淆矩阵
对分类器来说,一个好得多的性能评估指标是混淆矩阵,为了计算混淆矩阵,首先你需要有一系列的预测值,这样才能将预测值与真实值做比较。你或许想在测试集上做预测。但是我们现在先不碰它。(记住,只有当你处于项目的尾声,当你准备上线一个分类器的时候,你才应该使用测试集)。相反,你应该使用cross_val_predict()函数
1 | from sklearn.model_selection import cross_val_predict |
就像 cross_val_score(),cross_val_predict()也使用 K 折交叉验证。它不是返回一个评估分数,而是返回基于每一个测试折做出的一个预测值。这意味着,对于每一个训练集的样例,你得到一个干净的预测(“干净”是说一个模型在训练过程当中没有用到测试集的数据)。
现在使用 confusion_matrix()函数,你将会得到一个混淆矩阵。传递目标类(y_train_5)和预测类(y_train_pred)给它。
1 | from sklearn.metrics import confusion_matrix |
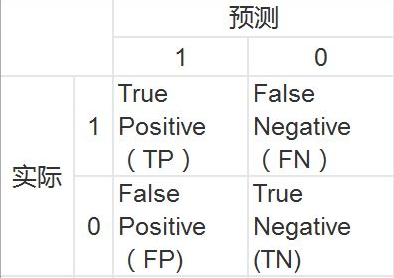
混淆矩阵中的每一行表示一个实际的类, 而每一列表示一个预测的类。该矩阵的第一行认为“非 5”(反例)中的 53272 张被正确归类为 “非 5”(他们被称为真反例,true negatives), 而其余 1307 被错误归类为”是 5” (假正例,false positives)。第二行认为“是 5” (正例)中的 1077 被错误地归类为“非 5”(假反例,false negatives),其余 4344 正确分类为 “是 5”类(真正例,true positives)。一个完美的分类器将只有真反例和真正例,所以混淆矩阵的非零值仅在其主对角线(左上至右下)。
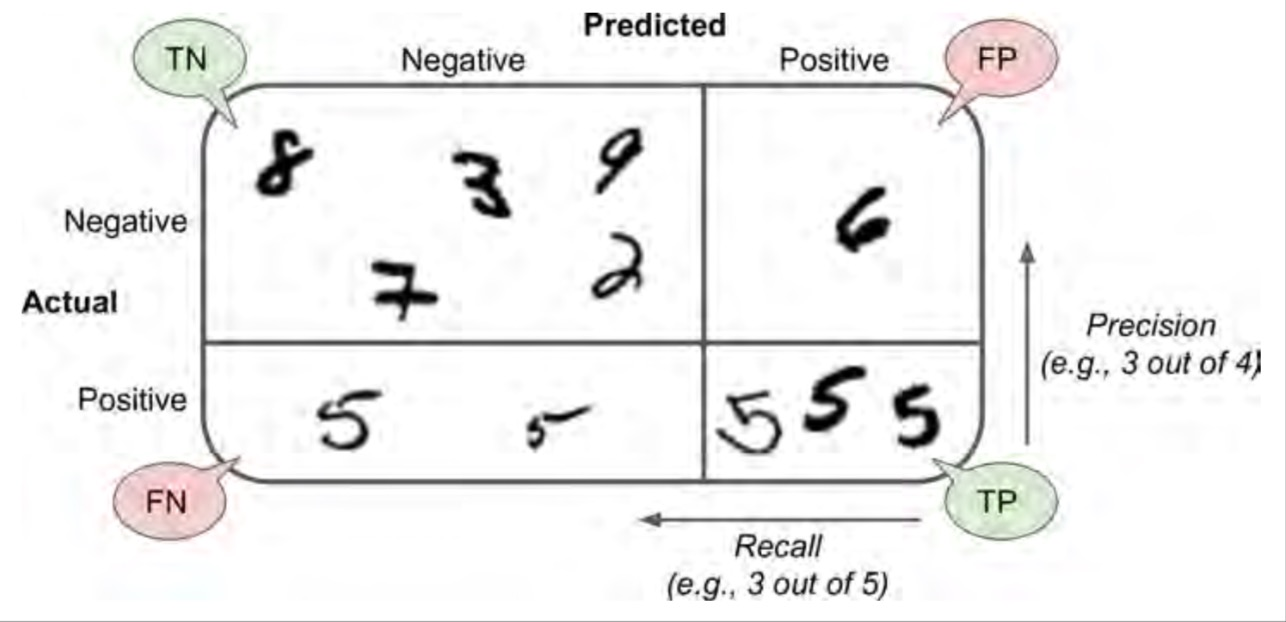
Scikit-Learn 提供了一些函数去计算分类器的指标,包括精确率和召回率(之前的文章是tensorflow,这里主要讲Scikit-Learn)
1 | from sklearn.metrics import precision_score, recall_score |
通常结合精确率和召回率会更加方便,这个指标叫做“F1 值”,特别是当你需要一个简单的方法去比较两个分类器的优劣的时候。F1 值是精确率和召回率的调和平均。普通的平均值平等地看待所有的值,而调和平均会给小的值更大的权重。所以,要想分类器得到一个高的 F1 值,需要召回率和精确率。
为了计算 F1 值,简单调用f1_score()
1 | from sklearn.metrics import f1_score |
F1 支持那些有着相近精确率和召回率的分类器。这不会总是你想要的。有的场景你会绝大程度地关心精确率,而另外一些场景你会更关心召回率。不幸的是,你不能同时拥有两者。增加精确率会降低召回率,反之亦然。这叫做精确率与召回率之间的折衷. 一般来说,提高分类阈值会减少假正例,从而提高精确率。降低分类阈值会提高召回率。
Scikit-Learn 不让你直接设置阈值,但是它给你提供了设置决策分数的方法,这个决策分数可以用来产生预测。它不是调用分类器的predict()方法,而是调用decision_function()方法。这个方法返回每一个样例的分数值,然后基于这个分数值,使用你想要的任何阈值做出预测。
1 | y_scores = sgd_clf.decision_function([some_digit]) |
SGDClassifier用了一个等于 0 的阈值,所以前面的代码返回了跟predict()方法一样的结果(都返回了true)。让我们提高这个阈值:
1 | threshold = 200000 |
这证明了提高阈值会降调召回率。这个图片实际就是数字 5,当阈值等于 0 的时候,分类器可以探测到这是一个 5,当阈值提高到 20000 的时候,分类器将不能探测到这是数字 5。
那么,你应该如何使用哪个阈值呢?首先,你需要再次使用cross_val_predict()得到每一个样例的分数值,但是这一次指定返回一个决策分数,而不是预测值。
1 | y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, |
现在有了这些分数值。对于任何可能的阈值,使用precision_recall_curve(),你都可以计算精确率和召回率:
1 | from sklearn.metrics import precision_recall_curve |
最后,你可以使用 Matplotlib 画出精确率和召回率,这里把精确率和召回率当作是阈值的一个函数。
1 | def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): |
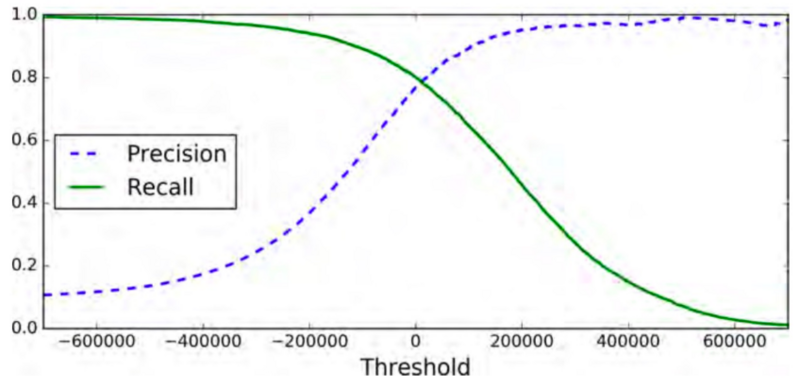
你也许会好奇为什么精确率曲线比召回率曲线更加起伏不平(右上部分)。原因是精确率有时候会降低,尽管当你提高阈值的时候,通常来说精确率会随之提高。另一方面,当阈值提高时候,召回率只会降低。这也就说明了为什么召回率的曲线更加平滑。
现在你可以选择适合你任务的最佳阈值。另一个选出好的精确率/召回率折衷的方法是直接画出精确率对召回率的曲线(PR曲线),如图所示。
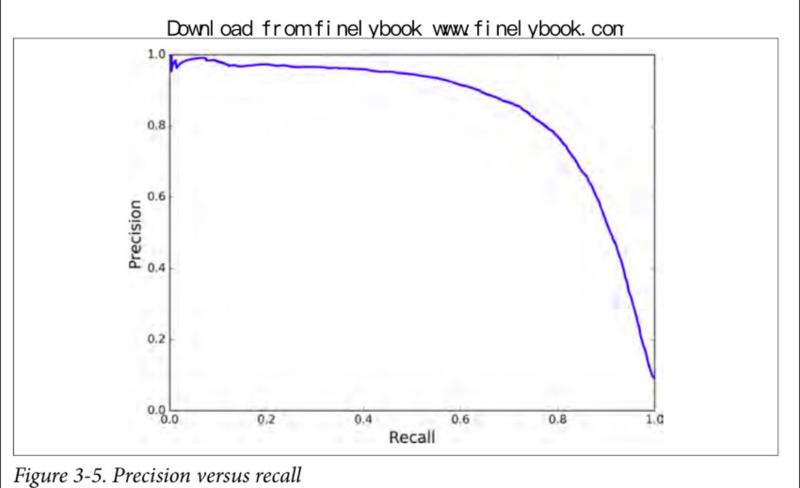
我们假设你决定达到 90% 的准确率,在 70000 附近找到一个阈值。为了作出预测(目前为止只在训练集上预测),你可以运行以下代码,而不是运行分类器的predict()方法。
1 | y_train_pred_90 = (y_scores > 70000) |
检查这些预测的准确率和召回率:
1 | precision_score(y_train_5, y_train_pred_90) |
ROC 曲线
受试者工作特征(ROC)曲线是另一个二分类器常用的工具。它非常类似与准确率/召回率曲线(PR曲线),但不是画出准确率对召回率的曲线,ROC 曲线是真正例率(true positive rate,另一个名字叫做召回率)对假正例率(false positive rate, FPR)的曲线。FPR 是反例被错误分成正例的比率。它等于 1 减去真反例率(true negative rate, TNR)。TNR是反例被正确分类的比率。TNR也叫做特异性。所以 ROC 曲线画出召回率对(1 减特异性)的曲线。
为了画出 ROC 曲线,你首先需要计算各种不同阈值下的 TPR、FPR,使用roc_curve()函数:
1 | from sklearn.metrics import roc_curve |
然后你可以使用 matplotlib,画出 FPR 对 TPR 的曲线
1 | def plot_roc_curve(fpr, tpr, label=None): |
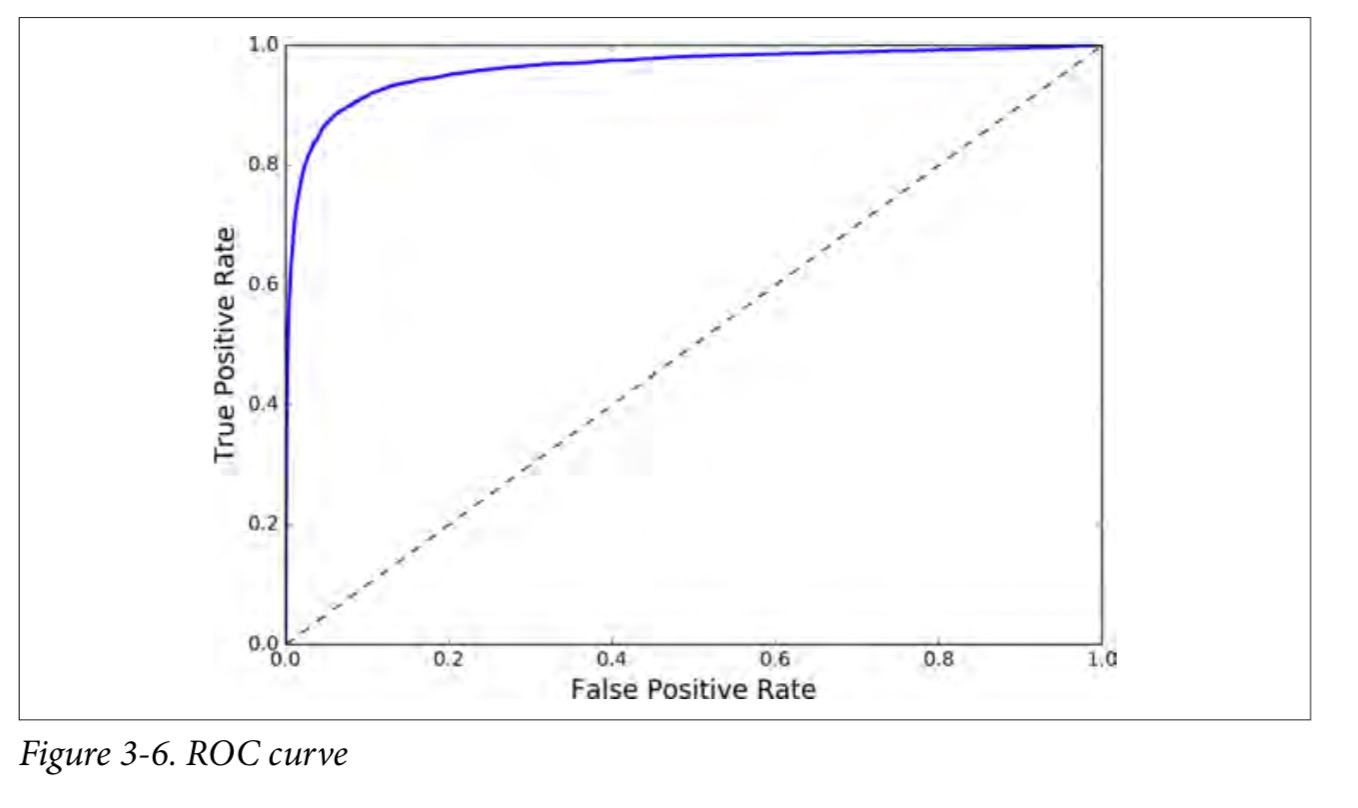
一个比较分类器之间优劣的方法是:测量ROC曲线下的面积(AUC)**。一个完美的分类器的 ROC AUC 等于 1,而一个纯随机分类器的 ROC AUC 等于 0.5。Scikit-Learn 提供了一个函数来计算 ROC AUC:
1 | from sklearn.metrics import roc_auc_score |
因为 ROC 曲线跟准确率/召回率曲线(或者叫 PR)很类似,你或许会好奇如何决定使用哪一个曲线呢?一个笨拙的规则是,优先使用 PR 曲线当正例很少,或者当你关注假正例多于假反例的时候。其他情况使用 ROC 曲线。举例子,回顾前面的 ROC 曲线和 ROC AUC 数值,你或许人为这个分类器很棒。但是这几乎全是因为只有少数正例(“是 5”),而大部分是反例(“非 5”)。相反,PR 曲线清楚显示出这个分类器还有很大的改善空间(PR 曲线应该尽可能地靠近右上角)。
我们训练一个RandomForestClassifier,然后拿它的的ROC曲线和ROC AUC数值去跟SGDClassifier的比较。首先你需要得到训练集每个样例的数值。但是由于随机森林分类器的工作方式,RandomForestClassifier不提供decision_function()方法。相反,它提供了predict_proba()方法。Skikit-Learn分类器通常二者中的一个。predict_proba()方法返回一个数组,数组的每一行代表一个样例,每一列代表一个类。数组当中的值的意思是:给定一个样例属于给定类的概率。比如,70%的概率这幅图是数字 5。
1 | from sklearn.ensemble import RandomForestClassifier |
但是要画 ROC 曲线,你需要的是样例的分数,而不是概率。一个简单的解决方法是使用正例的概率当作样例的分数。
1 | y_scores_forest = y_probas_forest[:, 1] # score = proba of positive class 预测为正例概率 |
现在你即将得到 ROC 曲线。将前面一个分类器的 ROC 曲线一并画出来是很有用的,可以清楚地进行比较。
1 | plt.plot(fpr, tpr, "b:", label="SGD") |
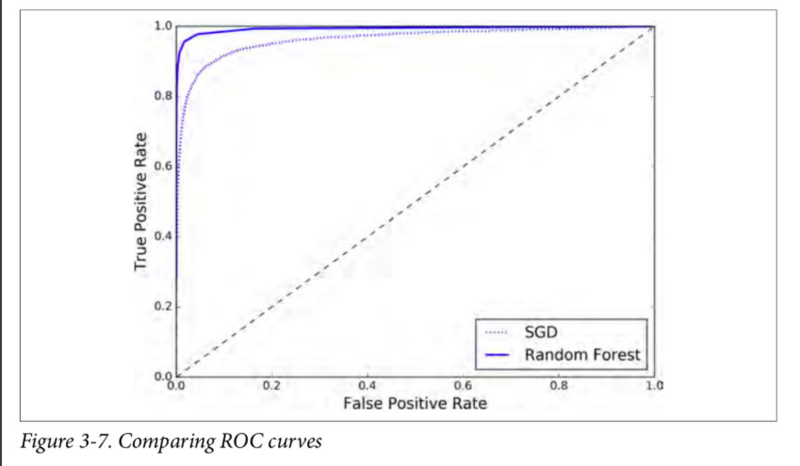
如你所见,RandomForestClassifier的 ROC 曲线比SGDClassifier的好得多:它更靠近左上角。所以,它的 ROC AUC 也会更大。
1 | roc_auc_score(y_train_5, y_scores_forest) |
现在你知道如何训练一个二分类器,选择合适的标准,使用交叉验证去评估你的分类器,选择满足你需要的准确率/召回率折衷方案,和比较不同模型的 ROC 曲线和 ROC AUC 数值。现在让我们检测更多的数字,而不仅仅是一个数字 5。
多类别分类
一些算法(比如随机森林分类器或者朴素贝叶斯分类器)可以直接处理多类分类问题。其他一些算法(比如 SVM 分类器或者线性分类器)则是严格的二分类器。然后,有许多策略可以让你用二分类器去执行多类分类。
- 一个方法是:训练10个二分类器,每一个对应一个数字(探测器 0,探测器 1,探测器 2,以此类推)。然后当你想对某张图片进行分类的时候,让每一个分类器对这个图片进行分类,选出决策分数最高的那个分类器(One vs all 里面分数最高的One)。这叫做“一对所有”(OvA)策略
- 另一个策略是对每一对数字都训练一个二分类器:一个分类器用来处理数字 0 和数字 1,一个用来处理数字 0 和数字 2,一个用来处理数字 1 和 2,以此类推。这叫做“一对一”(OvO)策略。如果有 N 个类。你需要训练N*(N-1)/2个分类器。
一些算法(比如 SVM 分类器)在训练集的大小上很难扩展,所以对于这些算法,OvO 是比较好的,因为它可以在小的数据集上面可以更多地训练,较之于巨大的数据集而言。但是,对于大部分的二分类器来说,OvA 是更好的选择。Scikit-Learn 可以探测出你想使用一个二分类器去完成多分类的任务,它会自动地执行 OvA(除了 SVM 分类器,它使用 OvO)让我们试一下SGDClassifier.
1 | sgd_clf.fit(X_train, y_train) # y_train, not y_train_5 |
上面的代码在训练集上训练了一个SGDClassifier。这个分类器处理原始的目标class,从 0 到 9(y_train),而不是仅仅探测是否为 5 (y_train_5)。然后它做出一个判断(在这个案例下只有一个正确的数字)。在幕后,Scikit-Learn 实际上训练了 10 个二分类器,每个分类器都产到一张图片的决策数值,选择数值最高的那个类。
为了证明这是真实的,你可以调用decision_function()方法。不是返回每个样例的一个数值,而是返回 10 个数值,一个数值对应于一个类。
1 | some_digit_scores = sgd_clf.decision_function([some_digit]) |
最高数值是对应于类别 5 :
1 | np.argmax(some_digit_scores) # 找最大值的索引 |
一个分类器被训练好了之后,它会保存目标类别列表到它的属性classes_ 中去,按照值排序。在本例子当中,在classes_ 数组当中的每个类的索引方便地匹配了类本身,比如,索引为 5 的类恰好是类别 5 本身。但通常不会这么幸运。
如果你想强制 Scikit-Learn 使用 OvO 策略或者 OvA 策略,你可以使用OneVsOneClassifier类或者OneVsRestClassifier类。创建一个样例,传递一个二分类器给它的构造函数。举例子,下面的代码会创建一个多类分类器,使用 OvO 策略,基于SGDClassifier。
1 | from sklearn.multiclass import OneVsOneClassifier |
训练一个RandomForestClassifier同样简单:
1 | forest_clf.fit(X_train, y_train) |
这次 Scikit-Learn 没有必要去运行 OvO 或者 OvA,因为随机森林分类器能够直接将一个样例分到多个类别。你可以调用predict_proba(),得到样例对应的类别的概率值的列表:
1 | forest_clf.predict_proba([some_digit]) |
你可以看到这个分类器相当确信它的预测:在数组的索引 5 上的 0.8,意味着这个模型以 80% 的概率估算这张图片代表数字 5。它也认为这个图片可能是数字 0 或者数字 3,分别都是 10% 的几率。
现在当然你想评估这些分类器。像平常一样,你想使用交叉验证。让我们用cross_val_score()来评估SGDClassifier的精度。
1 | cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy") |
在所有测试折(test fold)上,它有 84% 的精度。如果你是用一个随机的分类器,你将会得到 10% 的正确率。所以这不是一个坏的分数,但是你可以做的更好。举例子,简单将输入正则化,将会提高精度到 90% 以上。
1 | from sklearn.preprocessing import StandardScaler |
误差分析:
首先,你可以检查混淆矩阵。你需要使用cross_val_predict()做出预测,然后调用confusion_matrix()函数,像你早前做的那样。
1 | y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3) |
这里是一对数字。使用 Matplotlib 的matshow()函数,将混淆矩阵以图像的方式呈现,将会更加方便
1 | plt.matshow(conf_mx, cmap=plt.cm.gray) # #灰度图,对应位置的值越大色块越亮 |

这个混淆矩阵看起来相当好,因为大多数的图片在主对角线上。在主对角线上意味着被分类正确。数字 5 对应的格子看起来比其他数字要暗淡许多。这可能是数据集当中数字 5 的图片比较少,又或者是分类器对于数字 5 的表现不如其他数字那么好。你可以验证两种情况.
让我们关注仅包含误差数据的图像呈现。首先你需要将混淆矩阵的每一个值除以相应类别的图片的总数目。这样子,你可以比较错误率,而不是绝对的错误数(这对大的类别不公平)。
1 | row_sums = conf_mx.sum(axis=1, keepdims=True) |
现在让我们用 0 来填充对角线。这样子就只保留了被错误分类的数据。让我们画出这个结果。(此时数值为错误率)
1 | np.fill_diagonal(norm_conf_mx, 0) |

现在你可以清楚看出分类器制造出来的各类误差。记住:行代表实际类别,列代表预测的类别。第 8、9 列相当亮,这告诉你许多图片被误分成数字 8 或者数字 9。相似的,第 8、9 行也相当亮,告诉你数字 8、数字 9 经常被误以为是其他数字。相反,一些行相当黑,比如第一行:这意味着大部分的数字 1 被正确分类(一些被误分类为数字 8 )。留意到误差图不是严格对称的。举例子,比起将数字 8 误分类为数字 5 的数量,有更多的数字 5 被误分类为数字 8。
分析混淆矩阵通常可以给你提供深刻的见解去改善你的分类器。回顾这幅图,看样子你应该努力改善分类器在数字 8 和数字 9 上的表现,和纠正 3/5 的混淆。举例子,你可以尝试去收集更多的数据,或者你可以构造新的、有助于分类器的特征。举例子,写一个算法去数闭合的环(比如,数字 8 有两个环,数字 6 有一个, 5 没有)。又或者你可以预处理图片(比如,使用 Scikit-Learn,Pillow, OpenCV)去构造一个模式,比如闭合的环。
分析独特的误差,是获得关于你的分类器是如何工作及其为什么失败的洞见的一个好途径。但是这相对难和耗时。举例子,我们可以画出数字 3 和 5 的例子
1 | cl_a, cl_b = 3, 5 |

左边两个5*5的块将数字识别为 3,右边的将数字识别为 5。一些被分类器错误分类的数字(比如左下角和右上角的块)是书写地相当差,甚至让人类分类都会觉得很困难(比如第 8 行第 1 列的数字 5,看起来非常像数字 3 )。但是,大部分被误分类的数字,在我们看来都是显而易见的错误。很难明白为什么分类器会分错。原因是我们使用的简单的SGDClassifier,这是一个线性模型。它所做的全部工作就是分配一个类权重给每一个像素,然后当它看到一张新的图片,它就将加权的像素强度相加,每个类得到一个新的值。所以,因为 3 和 5 只有一小部分的像素有差异,这个模型很容易混淆它们。
3 和 5 之间的主要差异是连接顶部的线和底部的线的细线的位置。如果你画一个 3,连接处稍微向左偏移,分类器很可能将它分类成 5。反之亦然。换一个说法,这个分类器对于图片的位移和旋转相当敏感。所以,减轻 3/5 混淆的一个方法是对图片进行预处理,确保它们都很好地中心化和不过度旋转。这同样很可能帮助减轻其他类型的错误。
多标签分类
先看一个简单点的例子,仅仅是为了阐明的目的
1 | from sklearn.neighbors import KNeighborsClassifier |
这段代码创造了一个y_multilabel数组,里面包含两个目标标签。第一个标签指出这个数字是否为大数字(7,8 或者 9),第二个标签指出这个数字是否是奇数。接下来几行代码会创建一个KNeighborsClassifier样例(它支持多标签分类,但不是所有分类器都可以),然后我们使用多目标数组来训练它。现在你可以生成一个预测,然后它输出两个标签:
1 | knn_clf.predict([some_digit]) |
它工作正确。数字 5 不是大数(False),同时是一个奇数(True)
有许多方法去评估一个多标签分类器,和选择正确的量度标准,这取决于你的项目。举个例子,一个方法是对每个个体标签去量度 F1 值(或者前面讨论过的其他任意的二分类器的量度标准),然后计算平均值。下面的代码计算全部标签的平均 F1 值:
1 | y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_train, cv=3) |
这里假设所有标签有着同等的重要性,但可能不是这样。特别是,如果你的 Alice 的照片比 Bob 或者 Charlie 更多的时候,也许你想让分类器在 Alice 的照片上具有更大的权重。一个简单的选项是:给每一个标签的权重等于它的支持度(比如,那个标签的样例的数目)。为了做到这点,简单地在上面代码中设置average=”weighted”。
多输出分类
我们即将讨论的最后一种分类任务被叫做“多输出-多类分类”(或者简称为多输出分类)。它是多标签分类的简单泛化,在这里每一个标签可以是多类别的(比如说,它可以有多于两个可能值)。
为了说明这点,我们建立一个系统,它可以去除图片当中的噪音。它将一张混有噪音的图片作为输入,期待它输出一张干净的数字图片,用一个像素强度的数组表示,就像 MNIST 图片那样。注意到这个分类器的输出是多标签的(一个像素一个标签)和每个标签可以有多个值(像素强度取值范围从 0 到 255)。所以它是一个多输出分类系统的例子。
分类与回归之间的界限是模糊的,比如这个例子。按理说,预测一个像素的强度更类似于一个回归任务,而不是一个分类任务。而且,多输出系统不限于分类任务。你甚至可以让你一个系统给每一个样例都输出多个标签,包括类标签和值标签。
让我们从 MNIST 的图片创建训练集和测试集开始,然后给图片的像素强度添加噪声,这里是用 NumPy 的randint()函数。目标图像是原始图像。
1 | noise = rnd.randint(0, 100, (len(X_train), 784)) |
让我们看一下测试集当中的一张图片(是的,我们在窥探测试集,所以你应该马上邹眉):
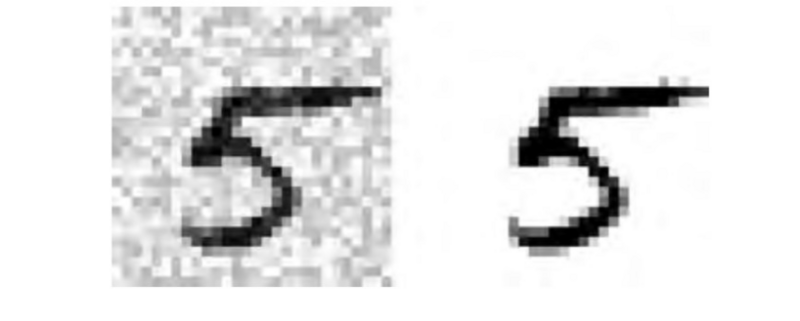
左边的加噪声的输入图片。右边是干净的目标图片。现在我们训练分类器,让它清洁这张图片:
1 | knn_clf.fit(X_train_mod, y_train_mod) |

到这里就讲完分类的内容了,有点混乱对不对,我们来总结梳理一下。
要掌握自定义k折交叉验证的方法(≈cross_val_score)
cross_val_score为验证模型的一个好方法,但是只能得到准确率的评估分数
如果正反例数据偏差大,我们需要用到混淆矩阵,这个矩阵要用到预测值而不是评估分数,所以改cross_val_predict,这会返回每个测试折做出的预测值,即y_train_pred
利用预测值y_train_pred可以得到混淆矩阵,精确率,召回率,F1
有时我们需要阈值来平衡精确率,召回率,而Scikit-Learn 不让你直接设置阈值,它会调用decision_function()方法。返回样例的分数值,然后基于这个分数值,使用你想要的任何阈值做出预测。
1
2
3
4
5
6y_scores = sgd_clf.decision_function([some_digit])
y_scores
array([ 161855.74572176])
threshold = 0
y_some_digit_pred = (y_scores > threshold)
array([ True], dtype=bool)每次都设定阈值不是一个完美的方法,如何才能找到合适的阈值呢?你需要再次使用cross_val_predict()得到每一个样例的分数值,但是这一次指定返回一个决策分数,而不是预测值。(阈值相关,就要进行打分)
1
2y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")现在有了这些分数值。对于任何可能的阈值,使用precision_recall_curve(),你都可以计算精确率和召回率;precisions, recalls, thresholds是任何阈值的范围值,可以变化曲线和PR曲线
1
2
3from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)与PR曲线另一个相关的是ROC曲线(TPR/FPR),为了画出 ROC 曲线,你首先需要计算各种不同阈值下的 TPR、FPR,使用roc_curve()函数(还是要打分);跳过ROC曲线(其实相当于已经做了),想直接计算出ROC AUC也行。
1
2
3
4
5from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)如果想得到RandomForestClassifier的ROC曲线,由于RandomForestClassifier不提供decision_function()方法,相反,它提供了predict_proba()方法(另外一种概率打分),返回概率值,此时用正例概率作为分值。例如70%的概率是垃圾邮件。
另外,因为 ROC 曲线跟准确率/召回率曲线(或者叫 PR)很类似,你或许会好奇如何决定使用哪一个曲线呢?一个笨拙的规则是,优先使用 PR 曲线当正例很少,或者当你关注假正例多于假反例的时候。其他情况使用 ROC 曲线
多类别分类有一对一ovo, 一对多ova两种方法,一般svm由于在训练集的大小上很难扩展,因为它可以在小的数据集上面可以更多地训练,故用ovo,其他大部分用ova。如果Scikit-Learn嗅探出你想做一个多分类任务,它会自动使用ova,svm训练器除外
误差分析,将混淆矩阵归一化后用图片色块输出,查看哪些类别经常被错误分类。