集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,比单一学习器获得显著优越的泛化性能。想要获得好的集成,个体学习器应”好而不同“,要保证准确性和多样性。要产生好而不同的个体学习器,恰是集成学习研究的核心
目前集成学习可分为两大类,即个体学习器之间有依赖关系,必须串行生成的序列化方法;以及个体学习器不存在强依赖关系,可同时生成的并行化方法。前者的代表是Boosting,最著名的是代表有Adaboost, GBDT和XGBOOST;后者的代表是Bagging和随机森林。对于学习器的结合策略有三大类:投票法(分类),平均法(连续数值),学习法(Stacking)
Boosting
Adaboost
算法思想
Adaboost提升方法是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注,于是,分类问题就被一系列的弱分类器“分而治之”。另外,对于弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率较大的弱分类器的权值,使其在表决中起较小的作用。(两个权重,一个是样本权重,另外一个是分类器的权重)
AdaboostBoost的算法的框架如下图所示
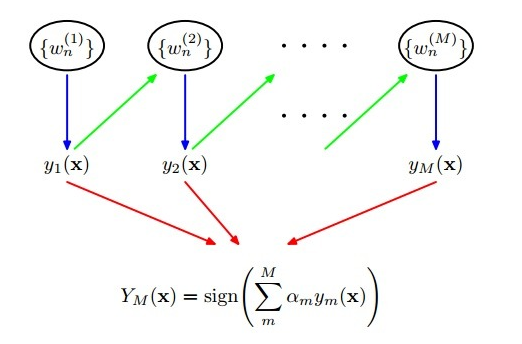
算法流程
具体算法流程如下图所示:

- step2. 预期迭代T轮
- step4. 计算分类器$h_t$的误差率$\epsilon_t$
这里$w_{ki}$表示第k轮(第k个分类器)中第i个实例的权重,$\sum_{i=1}^m{w_{ki}=1}$,I表示指示函数,代表满足条件的样本。这表明,误差率是被$h_t$分类错误的样本的权重之和。(这些样本的权重会在后面归一化)
- step5. 分类器比随机分类效果还差则停止
- step6. 根据误差率计算分类器的权重,表示最终分类器的重要程度。由表达式可知,当误差率小于等于1/2时,$\alpha_k$大于等于0。并且$\alpha_k$随着误差率的减小而增大,意味着误差越小的分类器最后的重要程度越大。
- step7. 更新样本权重,$Z_k$为归一化因子,把最后的全部样本权重求和即可。
Adaboost算法优缺点
Adaboost优点
- 不容易发生过拟合。
- Adaboost是一种有很高精度的分类器。
- 当使用简单分类器时,计算出的结果是可理解的。
- 可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
Adaboost缺点
- 训练时间过长。
- 执行效果依赖于弱分类器的选择。
- 对样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
GBTD
GBDT(Gradient Boosting Decision Tree)是一种迭代的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成思想进行了有效的结合。并且GBDT每一棵树都是回归树CART.。由于GBDT的核心在与累加所有树的结果作为最终结果,而分类树得到的离散分类结果对于预测分类并不是这么的容易叠加。这是区别于分类树的一个显著特征(毕竟男+女=是男是女?,这样的运算是毫无道理的),GBDT在运行时就使用到了回归树的这个性质,它将累加所有树的结果作为最终结果。所以GBDT中的树都是回归树,而不是分类树,它用来做回归预测,当然回归树经过调整之后也能用来做分类。
这里要先介绍GBDT简单版本的提升树Boosting Decision Tree,后面再介绍GBDT。
提升树Boosting Decision Tree
提升树(Boosting Decision Tree)由于输出样本是连续值,因此我们通过迭代多棵回归树来共同决策(之前CART只是拟合一颗完整的回归树)。回归树的构造在上一节已经介绍过了,不再赘述。
我们利用平方误差来表示损失函数,其中每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树。其中残差=真实值-预测值,提升树即是整个迭代过程生成的回归树的累加。提升树模型可以表示为决策树的加法模型:
其中$T\left(x;\varTheta_m\right)$表示决策树;$\varTheta_m$为决策树的参数;M为树的个数。
提升树的过程如下,节点下所有点的均值作为该节点的预测值,例如左图的15与25。(这里是将特征分开处理并缩小了树的规模,若用CART可能会出现深度为3的回归树)
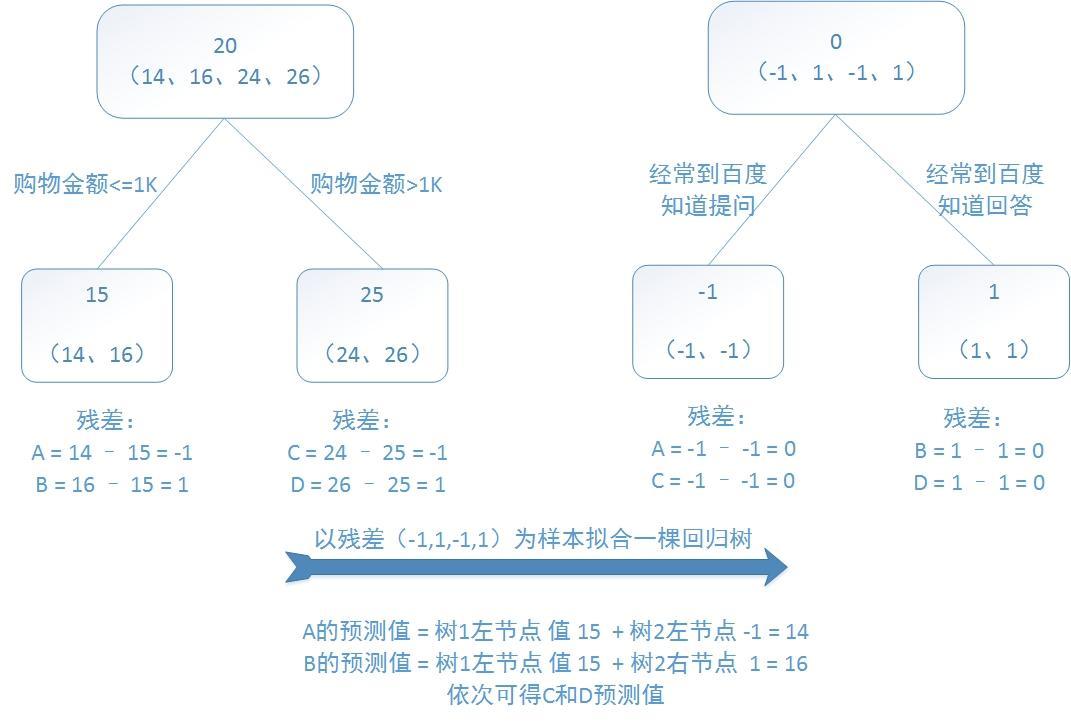
回归问题的提升树算法叙述如下:

对比初始的CART回归树与GBDT所生成的回归树,可以发现,最终的结果可能是相同的,那我们为什么还要使用GBDT呢?
- 答案就是对模型过拟合的考虑。过拟合是指为了让训练集精度更高,学到了很多“仅在训练集上成立的规律”,导致换一个数据集后,当前规律的预测精度就不足以使人满意了。毕竟,在训练精度和实际精度(或测试精度)之间,后者才是我们想要真正得到的。
- 在上面这个例子中,初始的回归树为达到100%精度使用了3个特征(上网时长、时段、网购金额),但观察发现,分枝“上网时长>1.1h”很显然过拟合了,不排除恰好A上网1.5h, B上网1小时,所以用上网时间是不是>1.1小时来判断所有人的年龄很显然是有悖常识的。
- 而在GBDT中,两棵回归树仅使用了两个特征(购物金额与对百度知道的使用方式)就实现了100%的预测精度,其分枝依据更合乎逻辑(当然这里是相比较于上网时长特征而言),算法在运行中也体现了“如无必要,勿增实体”的奥卡姆剃刀原理
梯度提升决策树Gradient Boosting Decision Tree
GBDT回归算法
提升树利用加法模型与向前分布算法实现学习的优化过程,即是通过迭代得到一系列的弱分类器,进而通过不同的组合策略得到相应的强学习器。在GBDT的迭代中,假设前一轮得到的强学习器为$f_{t−1}(x)$ ,对应的损失函数则为$L(y,f_{t−1}(x))$ 。因此新一轮迭代的目的就是找到一个弱学习器$h_t(x)$ ,使得损失函$L(y,f_{t−1}(x)+h_t(x))$ 达到最小。因此问题的关键就在于对损失函数的度量,这也正是难点所在。当损失函数是平方损失和指数损失时,每一步优化是很简单的。但对一般损失函数而言,往往每一步优化没那么容易,如绝对值损失函数和Huber损失函数。常见的损失函数及其梯度如下表所示:

那我们怎么样才能找到一种通用的拟合方法呢?针对这一问题,Freidman提出了梯度提升算法:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,进而拟合一个CART回归树。其中第t轮的第i个样本的损失函数的扶梯度表示为,右下角的等式是求偏导后带入计算的
负梯度作为回归问题中提升树算法的残差的近似值(与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例,拟合一个回归树),这就是梯度提升决策树。假设样本数据为m,最大的迭代次数为T。其算法过程如下:

- step1. 初始化弱分类器,计算出使损失函数极小化的一个常数值c,此时树仅有一个根结点。c的均值可取样本y的均值。这个初始化得到的c将用于第一次计算负梯度$f(x_i)=f(t-1)=f(0)$的代入计算得到残差近似值$r_{ti}$。(第t代第i个样本)
- step2(a) .计算每个样本的$r_{ti}$
- step2(b). 利用$(x_i,r_{ti})i=1,2,3,…,m$,我们可以拟合一颗CART回归树,得到第t棵回归树(注意回归树节点内的均值求法不再是我们想要的了),其对应的叶节点区域为$R_{tj},j=1,2,3,…,J$,其中J为叶子节点的个数。
- step2(c). 接下来,针对每一个叶子节点中的样本,要拟合叶子结点最好的输出值$c_{tj}$(不再是简单的求节点均值),使得求出的损失函数最小。回顾之前写的新一轮迭代的目的,这时候的输出值$c_{tj}$组成就是我们想要的第t棵弱学习器$h_t(x)$。其实就是在上一棵强学习器树稍加改变决策树中叶节点值,希望拟合的误差越来越小。
这样我们便得到本轮的弱学习器决策树拟合函数
- step2(d). 更新强学习器,上一个强学习器+弱学习器
- step3. 得到输出的最后一轮的最终强学习器模型(最大迭代T轮)
GBDT分类算法
GBDT分类算法在思想上和回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。为解决此问题,我们尝试用类似于逻辑回归的对数似然损失函数的方法,也就是说我们用的是类别的预测概率值和真实概率值来拟合损失函数。对于对数似然损失函数,我们有二元分类和多元分类的区别。
二元GBDT分类算法
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数表示为
其中y∈{−1,1}。则此时的负梯度误差为
对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
由于上式比较难优化,我们一般使用近似值代替
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索外,二元GBDT分类和GBDT回归算法过程相同。
多元GBDT分类算法
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假如类别数为K,则我们的对数似然函数为
其中如果样本输出类别为k,则$y_k=1$。第k类的概率$p_k(x)$的表达式为
集合上两式,我们可以计算出第t轮的第i个样本对应类别l的负梯度误差为
其实这里的误差就是样本i对应类别l的真实概率和t-1轮预测概率的差值。对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
由于上式比较难优化,我们用近似值代替
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。
XGBoost
数据建模中,经常采用Boosting方法通过将成百上千个分类准确率较低的树模型组合起来,成为一个准确率很高的预测模型。这个模型会不断地迭代,每次迭代就生成一颗新的树。但在数据集较复杂的时候,可能需要几千次迭代运算,这将造成巨大的计算瓶颈。
针对这个问题。华盛顿大学的陈天奇博士开发的XGBoost(eXtreme Gradient Boosting)基于C++通过多线程实现了回归树的并行构建,并在原有Gradient Boosting算法基础上加以改进,从而极大地提升了模型训练速度和预测精度.
梯度下降与牛顿法
在机器学习任务中,需要最小化损失函数L(θ),其中θ是要求解的模型参数。梯度下降法常用来求解这种无约束最优化问题,它是一种迭代方法:选取初值$θ^0$ ,不断迭代,更新θ的值,进行损失函数的极小化。
- 迭代公式:$θ^t = θ_{t-1}+△θ$
梯度下降:将$L(θ^t)$ 在$θ^{t-1}$ 处进行一阶泰勒展开:
要使得$L(θ^t)<L(θ^{t-1})$ ,可取$△θ=-\alpha L’(θ^{t-1})$ ,则$θ^t = θ^{t-1}-\alpha L’(θ^{t-1})$
这里$\alpha$ 是步长,可通过line search确定,但一般直接赋一个小的数
牛顿法:将$L(θ^t)$ 在$θ^{t-1}$ 处进行二阶泰勒展开:
可将一阶和二阶导数分别记为g 和 h,则:
要使得$L(θ^t)$极小,即让$g△θ+h\frac{(△θ)^2}{2}$ 极小,可令其对△θ求偏导值为0,求得$△θ=-\frac{g}{h}$ ,故$θ^t = θ^{t-1}+△θ=θ^{t-1}-\frac{g}{h}$ ,将其推广到向量形式,有$θ^t = θ^{t-1}-H^{-1}g$
GBDT 在函数空间中利用梯度下降法进行优化
XGBoost 在函数空间中用牛顿法进行优化
XGBoost的推导过程
定义目标函数
相比原始的GBDT,XGBoost的目标函数多了正则项,使得学习出来的模型更加不容易过拟合。有哪些指标可以衡量树的复杂度?树的深度,内部节点个数,叶子节点个数(T),叶节点分数(w)…
XGBoost采用的是:T代表叶子数量,w代表叶子预测权值
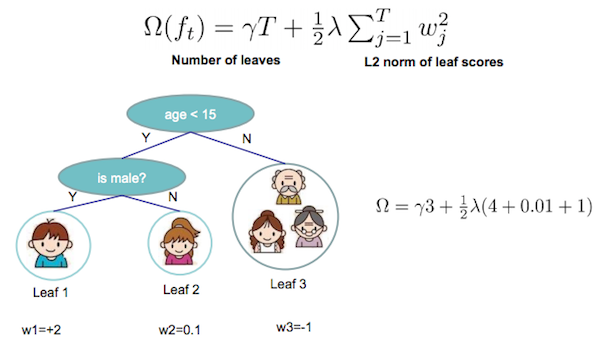
而XGBoost第t次迭代后,模型的预测等于前t-1次的模型预测加上第t棵树的预测

即每次迭代生成一棵新的回归树,从而使预测值不断逼近真实值(即进一步最小化目标函数)。每一次保留原来的模型不变,加入一个新的函数f到模型里面。其中$\hat{y}_i\left(t-1\right)$就是t-1轮的模型预测,$f_t{(x_i)}$为新t轮加入的预测函数。选取的$f_t{(x_i)}$必须使我们的目标函数尽量最大地降低(这里应用到了Boosting的基本思想,即当前的基学习器重点关注以前所有学习器犯错误的那些数据样本,以此来达到提升的效果)
此时目标损失函数可写作:
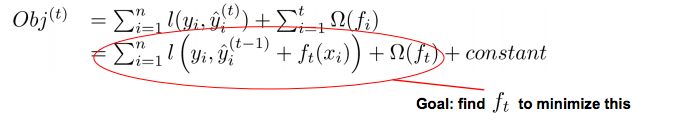
如果我们考虑平方误差作为损失函数,公式可改写为:
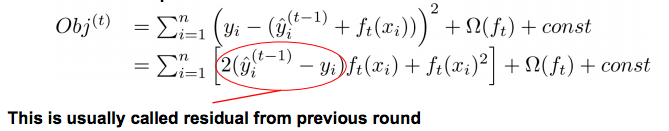
这里的化简没有看懂,感觉少了一项残差的平方。不过原等式$+f_t{(x_i)}$看做泰勒展开的$+\bigtriangleup x$ .
公式中$y_i,\widehat y_i$ 都是已知的,模型要学习的只有第t棵树$f_t$ .另外对于损失函数不是平方误差的情况,我们可以采用如下的泰勒展开近似来定义一个近似的目标函数,方便我们进行下一步的计算。其中$g_i$和$h_i$为损失函数对$\widehat y_i^{t-1}$的一阶和二阶倒数。
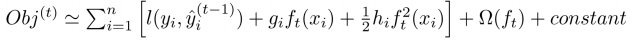
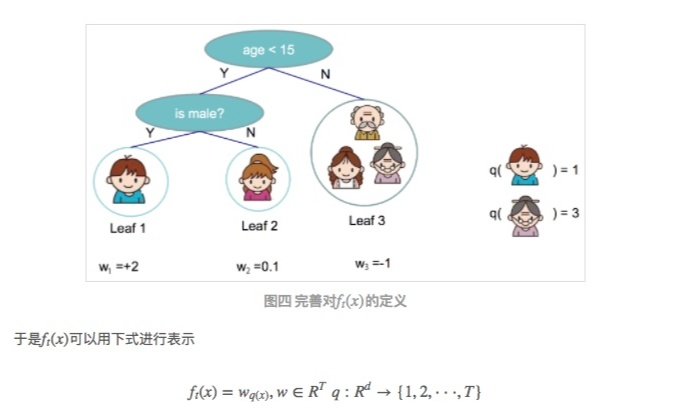
这时候,所有东西都准备好了,最后我们怎么定义$f_t$呢?它可以代表一颗具有预测结果的树,即叶子节点有预测权重。我们定义w为树叶的权重序列,q为树的结构,那么q(x)代表样本x落在树叶的位置。
目标函数的最小化
得到了目标函数,接下来是最关键的一步,在这种新的定义下,我们可以把目标函数进行如下改写,其中$I$被定义为每个叶子上面样本集合$I_j=\{i| q(x_i)=j\}$ 。$L(y_i,\widehat y_i^{t-1})$为真实值与前一个函数计算所得残差是已知的(我们都是在已知前一个树的情况下计算下一颗树的),同时,在同一个叶子节点上的数的函数值是相同的,可以做合并,于是:
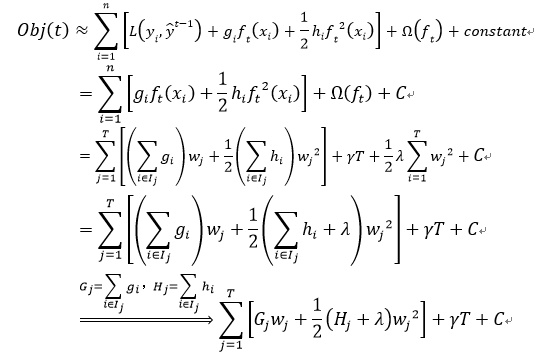
对上诉目标函数求导等于0,可以得到最后的结果:

得到这个目标函数,乍一看目标函数的计算与回归树的结构q函数没有什么关系,但是如果我们仔细回看目标函数的构成,就会发现其中$G_j$和$H_j$的取值是由第j个树叶上数据样本所决定的。而第jj个树上所具有的数据样本则是由树结构q函数决定的。也就是说,一旦回归树的结构q确定,那么相应的目标函数就能够根据上式计算出来。那么回归树的生成问题也就转换为找到一个最优的树结构q,使得它具有最小的目标函数。
计算求得的Obj目标函数代表了当指定一个树的结构的时候,目标函数上面最多减少多少。我们可以把它叫做结构分数(structure score)。可以把它认为是类似于基尼系数一样更加一般的对于树结构进行打分的函数。
当回归树的结构确定时,我们前面已经推导出其最优的叶节点分数以及对应的最小损失值,问题是怎么确定树的结构?才能让得到的结构分数最好,目标函数损失降低最大 。主要有以下两种方法
- 暴力枚举所有可能的树结构,选择损失值最小的 - NP难问题(树的结构有无穷种)
- 贪心法,每次尝试分裂一个叶节点,计算分裂前后的增益,选择增益最大的(主要)
确定树的结构(贪心法)
分裂前后的增益怎么计算?
- ID3算法采用信息增益
- C4.5算法采用信息增益比
- CART采用Gini系数
- XGBoost采用上诉优化函数的打分
即每一次尝试区队已有的叶子加入一个分割。对于一个剧透的分割方案,我们可以获得的增益可以由如下公式计算得到:
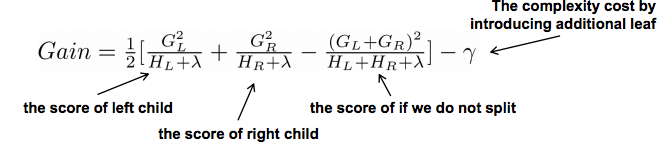
这个公式形式上跟ID3算法(采用信息熵计算增益)或者CART算法(采用基尼指数计算增益) 是一致的,都是用分裂后的某种值减去分裂前的某种值,从而得到增益。为了限制树的生长,我们可以加入阈值,当增益大于阈值时才让节点分裂,上式中的$\gamma$即阈值,它是正则项里叶子节点数T的系数,所以xgboost在优化目标函数的同时相当于做了预剪枝。另外,上式中还有一个系数$\lambda$,是正则项里leaf score的L2模平方的系数,对leaf score做了平滑,也起到了防止过拟合的作用,这个是传统GBDT里不具备的特性。
但需要注意是:引入的分割不一定会使得情况变好,因为在引入分割的同时也引入新叶子的惩罚项。所以通常需要设定一个阈值,如果引入的分割带来的增益小于一个阀值的时候,我们可以剪掉这个分割。此外在XGBoost的具体实践中,通常会设置树的深度来控制树的复杂度,避免单个树过于复杂带来的过拟合问题。
如何使用及参数

一些常见的问题
1、机器学习算法中GBDT和XGBOOST的区别有哪些?
2、为什么在实际的 kaggle 比赛中 gbdt 和 random forest 效果非常好?
3、 为什么xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
这里就不花时间写了,可以参考知乎和一些博客文章。
Bagging和随机森林
如果采样出的每个子集都完全不同,则每个基学习器只用到一小部分训练数据,甚至不足以进行有效学习,这显然无法确保产生出比较好的基学习器。为了解决这个问题,我们可考虑使用相互有交叠的采样子集。
Bagging
随机取出一个样本放入采样集中,再把该样本放回初始数据集。这样的自助采样过程还给 Bagging带来了另一个优点:由于每个基学习器只使用了初始训练集中约 63.2%的样本,剩下约 36.8%的样本可用作验证集来对泛化性能进行包外估计(out-of-bag estimate)。Bagging通常对分类任务使用简单的投票法,对回归任务使用简单平均法。
Bagging的算法描述如下所诉($D_{bs}$是自助采样产生的样本分布,输出采用投票法):

随机森林
随机森林(Random Forest)是Bagging的一个扩展变体。随机森林在以决策树为基学习器构建 Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;而在随机森林中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度:若令 k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分;一般情况下,推荐值 k=log2d.随机森林简单、容易实现、计算开销小.
随机森林的训练效率常优于 Bagging,因为在个体决策树的构建过程中,Bagging使用的是“确定型”决策树,在选择划分属性时要对结点的所有属性进行考察,而随机森林使用的“随机型”决策树则只需考察一个属性子集。
由于这些树是随机生成的,大部分的树对解决分类或回归问题是没有意义的,那么生成上万的树有什么好处呢?好处便是生成的决策树中有少数非常好的决策树。当你要做预测的时候,新的观察值随着决策树自上而下的预测并被赋予一个预测值或标签。一旦森林中的每棵树都有了预测值或标签,所有的预测结果将被归总到一起,所有树的投票做为最终的预测结果。简单来说,会像大数原理一样,抛硬币的次数接近无穷,其正反概率会越接近真实概率1/2。大部分的树会相互抵消,最后得到一个泛化较好的结果,从而得到一个好的预测结果。
学习器结合策略
假定集成包含 T 个基学习器h1,h2,…ht,其中hi在示例x上的输出为hi(x)下面介绍几种对hi进行结合的常见策略。
- 投票法 1)硬投票 2)相对多数投票 3)加权投票
- 平均法 1)简单平均法 2)加权平均法(较好)
- 学习法 1)Stacking
Stacking
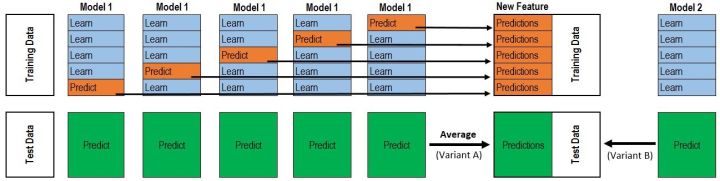
当训练数据很多时,一种更为强大的结合策略是使用“学习法”,即通过另一个学习器来进行结合。Stacking是学习法的典型代表。这里我们把个体学习器称为初级学习器,用于结合的学习器称为次级学习器或元学习(metalearner)。
Stacking先从初始数据集训练出初级学习器,然后“生成”一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当做样例输入特征,而初始样本的标记仍被当作样例标记。Stacking的算法描述如下,这里假定初级学习器使用不同的学习算法产生,即初级集成是异质的(初级学习器也可是同质的)。

train数据是初级训练器5折交叉得到的输出,test是初级训练器预测test后的均值
应用
投票分类
像我们之前讨论的一样,我们会在一个项目快结束的时候使用集成算法,一旦你建立了一些好的分类器,就把他们合并为一个更好的分类器。事实上,在机器学习竞赛中获得胜利的算法经常会包含一些集成方法。
接下来的代码创建和训练了在 sklearn 中的投票分类器。这个分类器由三个不同的分类器组成(训练集是第五章中的 moons 数据集):
1 | from sklearn.ensemble import RandomForestClassifier |
让我们看一下在测试集上的准确率:
1 | from sklearn.metrics import accuracy_score |
你看!投票分类器比其他单独的分类器表现的都要好。
如果所有的分类器都能够预测类别的概率(例如他们有一个predict_proba()方法),那么你就可以让 sklearn 以最高的类概率来预测这个类,平均在所有的分类器上。这种方式叫做软投票。他经常比硬投票表现的更好,因为它给予高自信的投票更大的权重。你可以通过把voting=”hard”设置为voting=”soft”来保证分类器可以预测类别概率。然而这不是 SVC 类的分类器默认的选项,所以你需要把它的probability hyperparameter设置为True(这会使 SVC 使用交叉验证去预测类别概率,其降低了训练速度,但会添加predict_proba()方法)。如果你修改了之前的代码去使用软投票,你会发现投票分类器正确率高达 91%
Bagging 和 Pasting
就像之前讲到的,可以通过使用不同的训练算法去得到一些不同的分类器。另一种方法就是对每一个分类器都使用相同的训练算法,但是在不同的训练集上去训练它们。有放回采样被称为装袋(Bagging,是 bootstrap aggregating 的缩写)。无放回采样称为粘贴(pasting)
换句话说,Bagging 和 Pasting 都允许在多个分类器上对训练集进行多次采样,但只有 Bagging 允许对同一种分类器上对训练集进行进行多次采样。
当所有的分类器被训练后,集成可以通过对所有分类器结果的简单聚合来对新的实例进行预测。聚合函数通常对分类是统计模式(例如硬投票分类器)或者对回归是平均。每一个单独的分类器在如果在原始训练集上都是高偏差,但是聚合降低了偏差和方差。通常情况下,集成的结果是有一个相似的偏差,但是对比与在原始训练集上的单一分类器来讲有更小的方差。
sklearn 中的 Bagging 和 Pasting
sklearn 为 Bagging 和 Pasting 提供了一个简单的API:BaggingClassifier类(或者对于回归可以是BaggingRegressor。接下来的代码训练了一个 500 个决策树分类器的集成,每一个都是在数据集上有放回采样 100 个训练实例下进行训练(这是 Bagging 的例子,如果你想尝试 Pasting,就设置bootstrap=False)。n_jobs参数告诉 sklearn 用于训练和预测所需要 CPU 核的数量。(-1 代表着 sklearn 会使用所有空闲核):
1 | >>>from sklearn.ensemble import BaggingClassifier |
如果基分类器可以预测类别概率(例如它拥有predict_proba()方法),那么BaggingClassifier会自动的运行软投票,这是决策树分类器的情况。
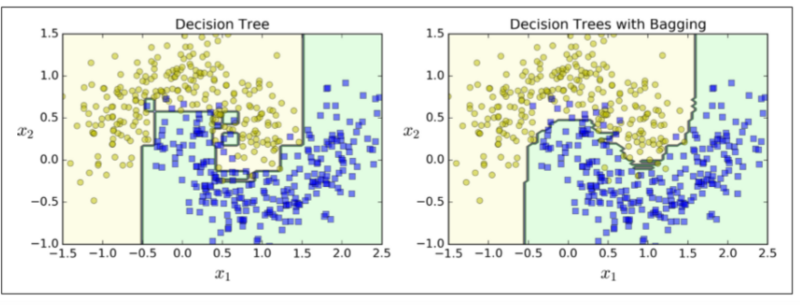
下图对比了单一决策树的决策边界和 Bagging 集成 500 个树的决策边界,两者都在 moons 数据集上训练。正如你所看到的,集成的分类比起单一决策树的分类产生情况更好:集成有一个可比较的偏差但是有一个较小的方差(它在训练集上的错误数目大致相同,但决策边界较不规则)。
Bootstrap 在每个预测器被训练的子集中引入了更多的分集,所以 Bagging 结束时的偏差比 Pasting 更高,但这也意味着预测因子最终变得不相关,从而减少了集合的方差。总体而言,Bagging 通常会导致更好的模型,这就解释了为什么它通常是首选的。然而,如果你有空闲时间和 CPU 功率,可以使用交叉验证来评估 Bagging 和 Pasting 哪一个更好。
Out-of-Bag 评价
对于 Bagging 来说,一些实例可能被一些分类器重复采样,但其他的有可能不会被采样。BaggingClassifier默认采样。BaggingClassifier默认是有放回的采样m个实例 (bootstrap=True),其中m是训练集的大小,这意味着平均下来只有63%的训练实例被每个分类器采样,剩下的37%个没有被采样的训练实例就叫做 Out-of-Bag 实例。注意对于每一个的分类器它们的 37% 不是相同的。
因为在训练中分类器从来没有看到过 oob 实例,所以它可以在这些实例上进行评估,而不需要单独的验证集或交叉验证。你可以拿出每一个分类器的 oob 来评估集成本身。
在 sklearn 中,你可以在训练后需要创建一个BaggingClassifier来自动评估时设置oob_score=True来自动评估。接下来的代码展示了这个操作。评估结果通过变量oob_score_来显示:
1 | bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,bootstrap=True, n_jobs=-1, oob_score=True) |
根据这个 obb 评估,BaggingClassifier可以再测试集上达到93.1%的准确率,让我们修改一下:
1 | from sklearn.metrics import accuracy_score |
我们在测试集上得到了 93.6% 的准确率,足够接近了!
对于每个训练实例 oob 决策函数也可通过oob_decision_function_变量来展示。在这种情况下(当基决策器有predict_proba()时)决策函数会对每个训练实例返回类别概率。例如,oob 评估预测第二个训练实例有 60.6% 的概率属于正类(39.4% 属于负类):
1 | bag_clf.oob_decision_function_ |
随机森林
正如我们所讨论的,随机森林是决策树的一种集成,通常是通过 bagging 方法(有时是 pasting 方法)进行训练,通常用max_samples设置为训练集的大小。与建立一个BaggingClassifier然后把它放入 DecisionTreeClassifier 相反,你可以使用更方便的也是对决策树优化够的RandomForestClassifier(对于回归是RandomForestRegressor)。接下来的代码训练了带有 500 个树(每个被限制为 16 叶子结点)的决策森林,使用所有空闲的 CPU 核:
1 | >>>from sklearn.ensemble import RandomForestClassifier |
除了一些例外,RandomForestClassifier使用DecisionTreeClassifier的所有超参数(决定数怎么生长),把BaggingClassifier的超参数加起来来控制集成本身
随机森林算法在树生长时引入了额外的随机;与在节点分裂时需要找到最好分裂特征相反,它在一个随机的特征集中找最好的特征。它导致了树的差异性,并且再一次用高偏差换低方差,总的来说是一个更好的模型。以下是BaggingClassifier大致相当于之前的randomforestclassifier:
1 | >>>bag_clf = BaggingClassifier(DecisionTreeClassifier(splitter="random", max_leaf_nodes=16),n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1) |
极端随机树
当你在随机森林上生长树时,在每个结点分裂时只考虑随机特征集上的特征(正如之前讨论过的一样)。相比于找到更好的特征我们可以通过使用对特征使用随机阈值使树更加随机(像规则决策树一样)。
这种极端随机的树被简称为 Extremely Randomized Trees(极端随机树),或者更简单的称为 Extra-Tree。再一次用高偏差换低方差。它还使得 Extra-Tree 比规则的随机森林更快地训练,因为在每个节点上找到每个特征的最佳阈值是生长树最耗时的任务之一。
你可以使用 sklearn 的ExtraTreesClassifier来创建一个 Extra-Tree 分类器。他的 API 跟RandomForestClassifier是相同的,相似的, ExtraTreesRegressor 跟RandomForestRegressor也是相同的 API。
我们很难去分辨ExtraTreesClassifier和RandomForestClassifier到底哪个更好。通常情况下是通过交叉验证来比较它们(使用网格搜索调整超参数)
特征重要度
最后,如果你观察一个单一决策树,重要的特征会出现在更靠近根部的位置,而不重要的特征会经常出现在靠近叶子的位置。因此我们可以通过计算一个特征在森林的全部树中出现的平均深度来预测特征的重要性。sklearn 在训练后会自动计算每个特征的重要度。你可以通过feature_importances_变量来查看结果。例如如下代码在 iris 数据集(第四章介绍)上训练了一个RandomForestClassifier模型,然后输出了每个特征的重要性。看来,最重要的特征是花瓣长度(44%)和宽度(42%),而萼片长度和宽度相对比较是不重要的(分别为 11% 和 2%):
1 | from sklearn.datasets import load_iris |
相似的,如果你在 MNIST 数据及上训练随机森林分类器(在第三章上介绍),然后画出每个像素的重要性,你可以得到下图
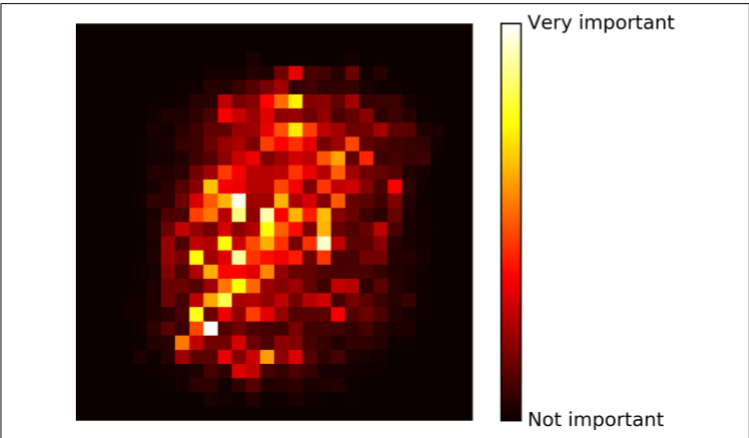
随机森林可以非常方便快速得了解哪些特征实际上是重要的,特别是你需要进行特征选择的时候
提升
下图显示连续五次预测的 moons 数据集的决策边界(在本例中,每一个分类器都是高度正则化带有 RBF 核的 SVM)。第一个分类器误分类了很多实例,所以它们的权重被提升了。第二个分类器因此对这些误分类的实例分类效果更好,以此类推。右边的图代表了除了学习率减半外(误分类实例权重每次迭代上升一半)相同的预测序列(误分类的样本权重提升速率即学习率)。你可以看出,序列学习技术与梯度下降很相似,除了调整单个预测因子的参数以最小化代价函数之外,AdaBoost 增加了集合的预测器,逐渐使其更好。
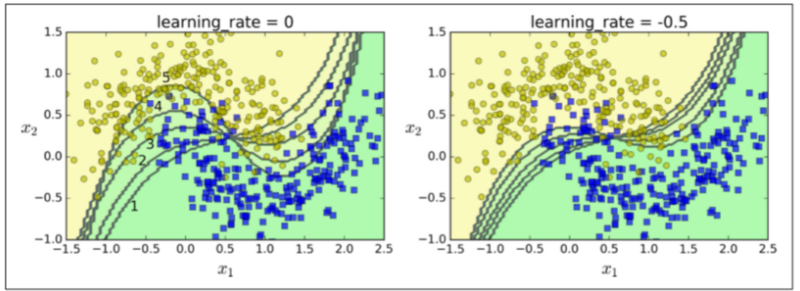
klearn 通常使用 Adaboost 的多分类版本 SAMME(这就代表了 分段加建模使用多类指数损失函数)。如果只有两类别,那么 SAMME 是与 Adaboost 相同的。如果分类器可以预测类别概率(例如如果它们有predict_proba()),如果 sklearn 可以使用 SAMME 叫做SAMME.R的变量(R 代表“REAL”),这种依赖于类别概率的通常比依赖于分类器的更好。
接下来的代码训练了使用 sklearn 的AdaBoostClassifier基于 200 个决策树桩 Adaboost 分类器(正如你说期待的,对于回归也有AdaBoostRegressor)。一个决策树桩是max_depth=1的决策树-换句话说,是一个单一的决策节点加上两个叶子结点。这就是AdaBoostClassifier的默认基分类器:
1 | >>>from sklearn.ensemble import AdaBoostClassifier |
如果你的 Adaboost 集成过拟合了训练集,你可以尝试减少基分类器的数量或者对基分类器使用更强的正则化。
梯度提升
另一个非常著名的提升算法是梯度提升。与 Adaboost 一样,梯度提升也是通过向集成中逐步增加分类器运行的,每一个分类器都修正之前的分类结果。然而,它并不像 Adaboost 那样每一次迭代都更改实例的权重,这个方法是去使用新的分类器去拟合前面分类器预测的残差 。
让我们通过一个使用决策树当做基分类器的简单的回归例子(回归当然也可以使用梯度提升)。这被叫做梯度提升回归树(GBRT,Gradient Tree Boosting 或者 Gradient Boosted Regression Trees)。首先我们用DecisionTreeRegressor去拟合训练集(例如一个有噪二次训练集):
1 | >>>from sklearn.tree import DecisionTreeRegressor |
现在在第一个分类器的残差上训练第二个分类器:
1 | >>>y2 = y - tree_reg1.predict(X) |
随后在第二个分类器的残差上训练第三个分类器:
1 | >>>y3 = y2 - tree_reg1.predict(X) |
现在我们有了一个包含三个回归器的集成。它可以通过集成所有树的预测来在一个新的实例上进行预测。
1 | >>>y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3)) |
下图左栏展示了这三个树的预测,在右栏展示了集成的预测。在第一行,集成只有一个树,所以它与第一个树的预测相似。在第二行,一个新的树在第一个树的残差上进行训练。在右边栏可以看出集成的预测等于前两个树预测的和。相同的,在第三行另一个树在第二个数的残差上训练。你可以看到集成的预测会变的更好。
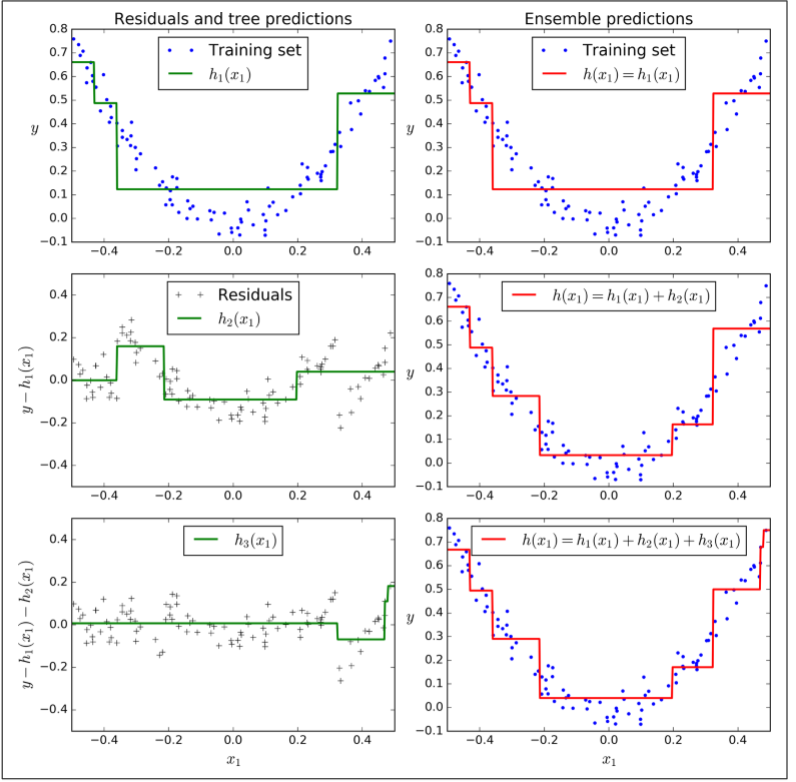
我们可以使用 sklean 中的GradientBoostingRegressor来训练 GBRT 集成。与RandomForestClassifier相似,它也有超参数去控制决策树的生长(例如max_depth,min_samples_leaf等等),也有超参数去控制集成训练,例如基分类器的数量(n_estimators)。接下来的代码创建了与之前相同的集成:
1 | >>>from sklearn.ensemble import GradientBoostingRegressor |
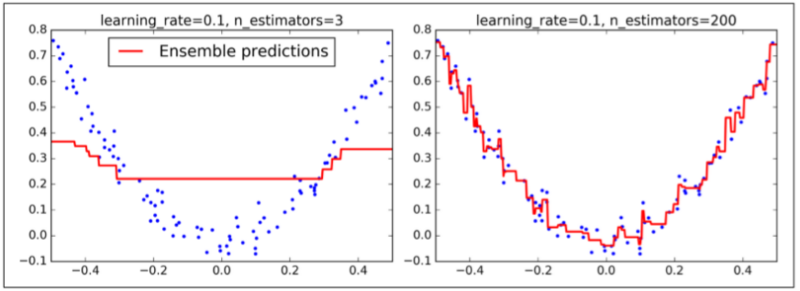
超参数learning_rate 确立了每个树的贡献。如果你把它设置为一个很小的树,例如 0.1,在集成中就需要更多的树去拟合训练集,但预测通常会更好。这个正则化技术叫做 shrinkage。下图 展示了两个在低学习率上训练的 GBRT 集成:其中左面是一个没有足够树去拟合训练集的树,右面是有过多的树过拟合训练集的树。
为了找到树的最优数量,你可以使用早停技术。最简单使用这个技术的方法就是使用staged_predict():它在训练的每个阶段(用一棵树,两棵树等)返回一个迭代器。加下来的代码用 120 个树训练了一个 GBRT 集成,然后在训练的每个阶段验证错误以找到树的最佳数量,最后使用 GBRT 树的最优数量训练另一个集成
1 | >>>import numpy as np |
验证错误在图的左面展示,最优模型预测被展示在右面
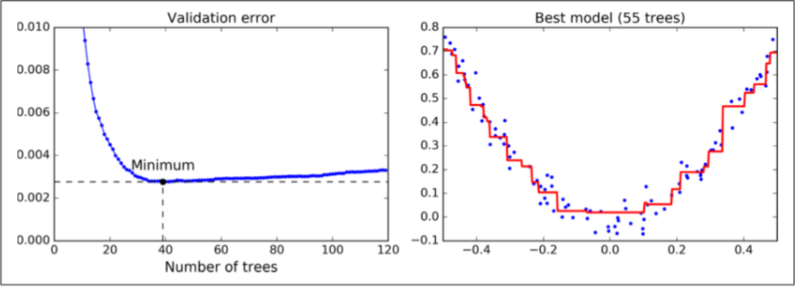
你也可以早早的停止训练来实现早停(与先在一大堆树中训练,然后再回头去找最优数目相反)。你可以通过设置warm_start=True来实现 ,这使得当fit()方法被调用时 sklearn 保留现有树,并允许增量训练。接下来的代码在当一行中的五次迭代验证错误没有改善时会停止训练:
1 | >>>gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True) |
GradientBoostingRegressor也支持指定用于训练每棵树的训练实例比例的超参数subsample。例如如果subsample=0.25,那么每个树都会在 25% 随机选择的训练实例上训练。你现在也能猜出来,这也是个高偏差换低方差的作用。它同样也加速了训练。这个技术叫做随机梯度提升。
也可能对其他损失函数使用梯度提升。这是由损失超参数控制(见 sklearn 文档)。
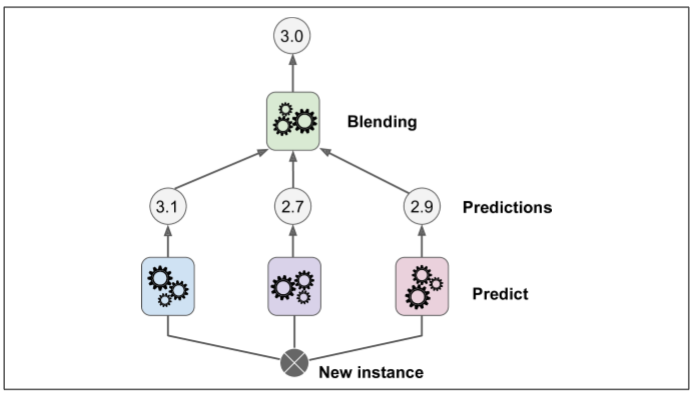
Stacking
本章讨论的最后一个集成方法叫做 Stacking(stacked generalization 的缩写)。这个算法基于一个简单的想法:不使用琐碎的函数(如硬投票)来聚合集合中所有分类器的预测,我们为什么不训练一个模型来执行这个聚合?图 展示了这样一个在新的回归实例上预测的集成。底部三个分类器每一个都有不同的值(3.1,2.7 和 2.9),然后最后一个分类器(叫做 blender 或者 meta learner )把这三个分类器的结果当做输入然后做出最终决策(3.0)
练习题
- 如果你在相同训练集上训练 5 个不同的模型,它们都有 95% 的准确率,那么你是否可以通过组合这个模型来得到更好的结果?如果可以那怎么做呢?如果不可以请给出理由。
- 软投票和硬投票分类器之间有什么区别?
- 是否有可能通过分配多个服务器来加速 bagging 集成系统的训练?pasting 集成,boosting 集成,随机森林,或 stacking 集成怎么样?
- out-of-bag 评价的好处是什么?
- 是什么使 极端随机树Extra-Tree 比规则随机森林更随机呢?这个额外的随机有什么帮助呢?那这个 Extra-Tree 比规则随机森林谁更快呢?
- 如果你的 Adaboost 模型欠拟合,那么你需要怎么调整超参数?
- 如果你的梯度提升过拟合,那么你应该调高还是调低学习率呢?
1、只要模型间多样性较大,组合成一个集合模型,会起到一定的效果。
2、硬投票分类器只计算集成中每个分类器的投票数,并选择得票最多的类。 软投票分类器计算每个类的平均估计概率,并选择具有最高概率的类。 软投票使概率大的类别权重更高,通常表现更好,但只有在可以估计类概率的分类器时才有效(例如,对于Scikit-Learn中的SVM分类器,您必须设置probability = True)。
3、 bagging,pasting,随机森林是可以的。boosting 集成因为学习器需要基于先前的学习器构建,因此训练是连续的,故不适合。至于stacking 集成,给定层中的所有预测变量彼此独立,因此可以在多个服务器上并行训练它们。 但是,一层中的预测变量只能在前一层中的预测变量都经过训练后才能进行训练。
4、未被训练过得实例可以当做验证集
5、在随机森林中,只考虑特征的随机子集并在每个节点处进行分割。 对于Extra-Trees也是如此,但它们更进一步:不是像常规决策树一样搜索最佳阈值,而是为每个特征使用随机阈值。 这种额外的随机性就像一种正则化的形式:如果随机森林过度拟合训练数据,极端随机树可能表现更好。 此外,由于Extra-Trees不会搜索最佳阈值,因此它们比随机森林训练要快得多。 然而,在做出预测时,它们既不比随机森林更快也不慢。
6、如果您的AdaBoost集合欠拟合,可以尝试增加学习器的数量或减少基本学习器的正则化超参数。 也可以尝试稍微提高学习率。
7、如果您的Gradient Boosting过拟合,应该尝试降低学习率。 你也可以使用早期停止法。