先看一个排序算法可视化大概了解一下经典的排序算法。
冒泡排序 BubbleSort
介绍
冒泡排序(bubble sort):每个回合都从第一个元素开始和它后面的元素比较,如果比它后面的元素更大的话就交换,一直重复,直到这个元素到了它能到达的位置。每次遍历都将剩下的元素中最大的那个放到了序列的“最后”(除去了前面已经排好的那些元素)。注意检测是否已经完成了排序,如果已完成就可以退出了。
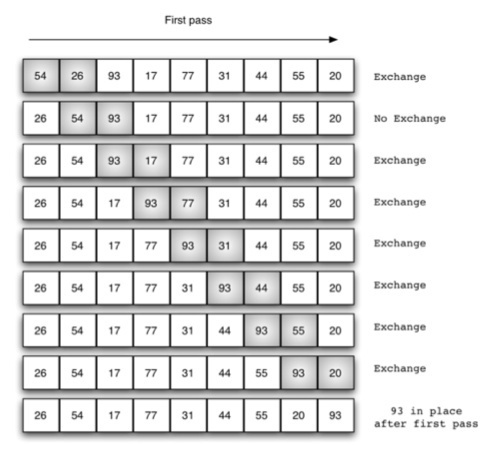
步骤
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
源代码
Python源代码(错误版本):
1 | def bubble_sort(arry): |
注:上述代码是没有问题的,但是实现却不是冒泡排序,而是选择排序(原理见选择排序),注意冒泡排序的本质是“相邻元素”的顺序交换,而非每次完成一个最小数字的选定。
Python源代码(正确版本):
1 | def bubble_sort(arry): |
优化1:
某一趟遍历如果没有数据交换,则说明已经排好序了,因此不用再进行迭代了。用一个标记记录这个状态即可。
Python源代码:
1 | def bubble_sort2(ary): |
选择排序 SelectionSort
介绍
每个回合都选择出剩下的元素中最大的那个,选择的方法是首先默认第一元素是最大的,如果后面的元素比它大的话,那就更新剩下的最大的元素值,找到剩下元素中最大的之后将它放入到合适的位置就行了。和冒泡排序类似,只是找剩下的元素中最大的方式不同而已。
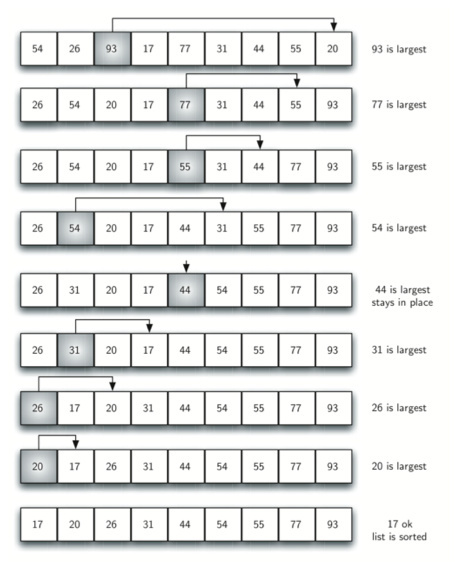
步骤
- 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 以此类推,直到所有元素均排序完毕。
源代码
1 | def select_sort(ary): |
插入排序 Insertion Sort
介绍
插入排序的工作原理是,对于每个未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 对具有nn个数据元素的序列进行排序时,插入排序需要进行n−1n−1趟插入。进行第j(1≥j≥n−1)j(1≥j≥n−1)趟插入时,前面已经有jj个元素排好序了,第jj趟将aj+1aj+1插入到已经排好序的序列中,这样既可使前面的j+1j+1个数据排好序。
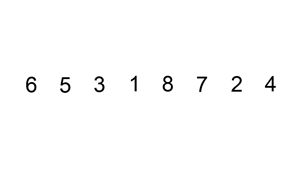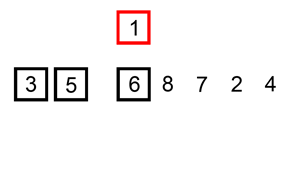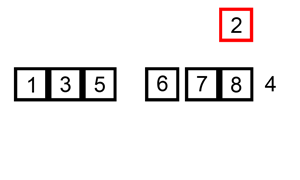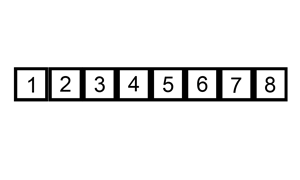
步骤
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果被扫描的元素(已排序)大于新元素,将该元素后移一位
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
源代码
1 | # 插入排序 |
希尔排序 ShellSort
介绍
希尔排序,也称递减增量排序算法,实质是分组插入排序。由 Donald Shell 于1959年提出。希尔排序是非稳定排序算法。
希尔排序的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
n=10的一个数组49, 38, 65, 97, 26, 13, 27, 49, 55, 4为例
第一次 gap = 10/2 = 5
49 38 65 97 26 13 27 49 55 4
1A 1B 2A 2B 3A 3B 4A 4B 5A 5B
1A, 1B, 2A, 2B等为分组标记,数字相同的表示在同一组,同组进行直接插入排序
第二次 gap = 5 / 2 = 2,排序后
13 27 49 55 4 49 38 65 97 26
1A 1B 1C 1D 1E 2A 2B 2C 2D 2E
第三次 gap = 2 / 2 = 1
4 26 13 27 38 49 49 55 97 65
1A 1B 1C 1D 1E 1F 1G 1H 1I 1J
第四次 gap = 1 / 2 = 0 排序完成得到数组:
4 13 26 27 38 49 49 55 65 97
源代码
1 | def shell_sort(ary): |
归并排序 Merge Sort
介绍
归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
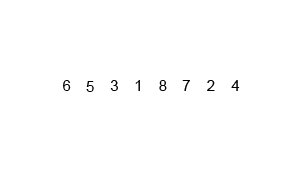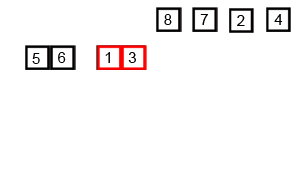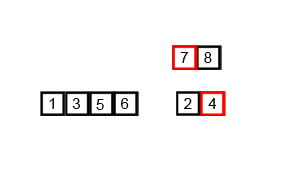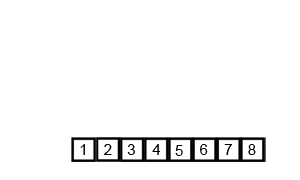
源代码
1 | # 归并排序 |
快速排序 QuickSort
介绍
快速排序是图灵奖得主C.R.A Hoare于1960年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法。分治法的基本思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题组合为原问题的解。
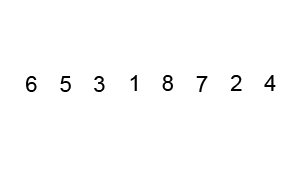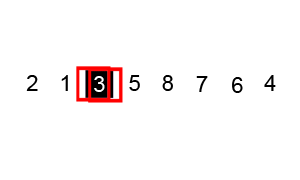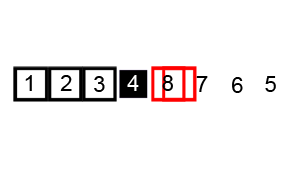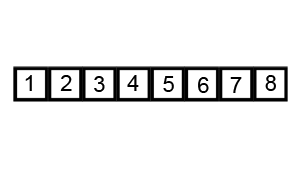
以一个数组作为示例,取区间第一个数为基准数。
0 1 2 3 4 5 6 7 8 9
72 6 57 88 60 42 83 73 48 85
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j–;
数组变为:
0 1 2 3 4 5 6 7 8 9
48 6 57 88 60 42 83 73 88 85
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
步骤
利用分治法可将快速排序分为三步:
- 从数列中挑出一个元素作为“基准”(pivot)。
- 分区过程,将比基准数大的放到右边,小于或等于它的数都放到左边。这个操作称为“分区操作”,分区操作结束后,基准元素所处的位置就是最终排序后它的位置
- 再对“基准”左右两边的子集不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
源代码
版本一
1 | def quick_sort(self, ary): |
版本二
1 | def quickSort(array): |
堆排序 HeapSort
介绍
堆排序在 top K 问题中使用比较频繁。堆排序是采用二叉堆的数据结构来实现的,虽然实质上还是一维数组。堆(二叉堆)可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示(普通的一般的二叉树通常用链表作为基本容器表示),每一个结点对应数组中的一个元素。
如下图,是一个堆和数组的相互关系,可看做堆的初始化
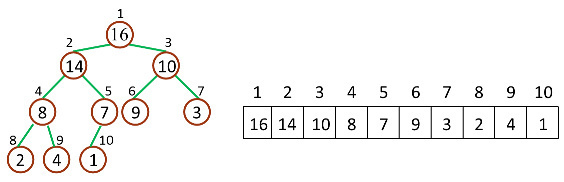
对于给定的某个结点的下标 i,可以很容易的计算出这个结点的父结点、孩子结点的下标:
- Parent(i) = floor(i/2),i 的父节点下标
- Left(i) = 2i,i 的左子节点下标
- Right(i) = 2i + 1,i 的右子节点下标
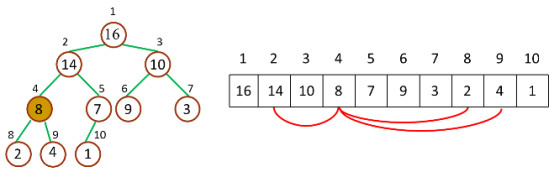
二叉堆具有以下性质:
- 父节点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
- 每个节点的左右子树都是一个二叉堆(都是最大堆或最小堆)。

步骤
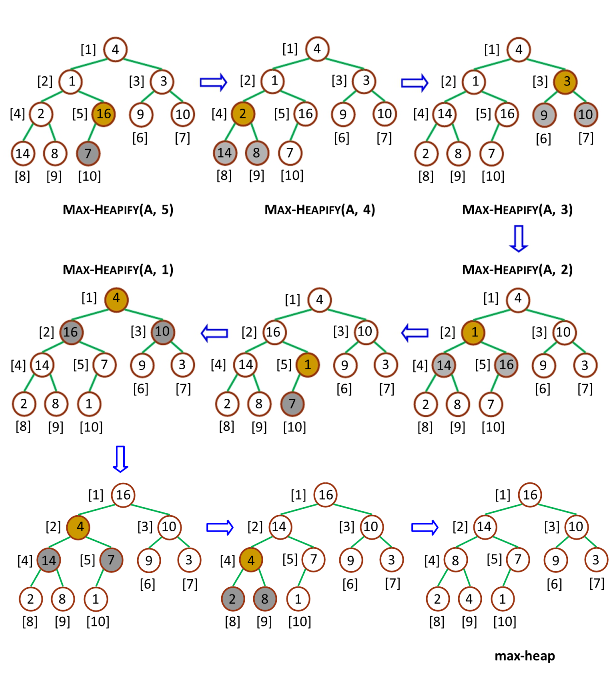
- 构造最大堆(Build_Max_Heap)自底向上:若数组下标范围为0~n,考虑到单独一个元素是大根堆,则从下标n/2开始的元素均为大根堆。于是只要从n/2-1开始(最后一个非叶子节点开始),分别与左孩子和右孩子比较大小,如果最大,则不用调整,否则和孩子中的值最大的一个交换位置,若交换之后还比此节点的孩子要小,继续向下交换(这里是自顶向下) 。并向前依次构造大根堆,这样就能保证,构造到某个节点时,它的左右子树都已经是大根堆。
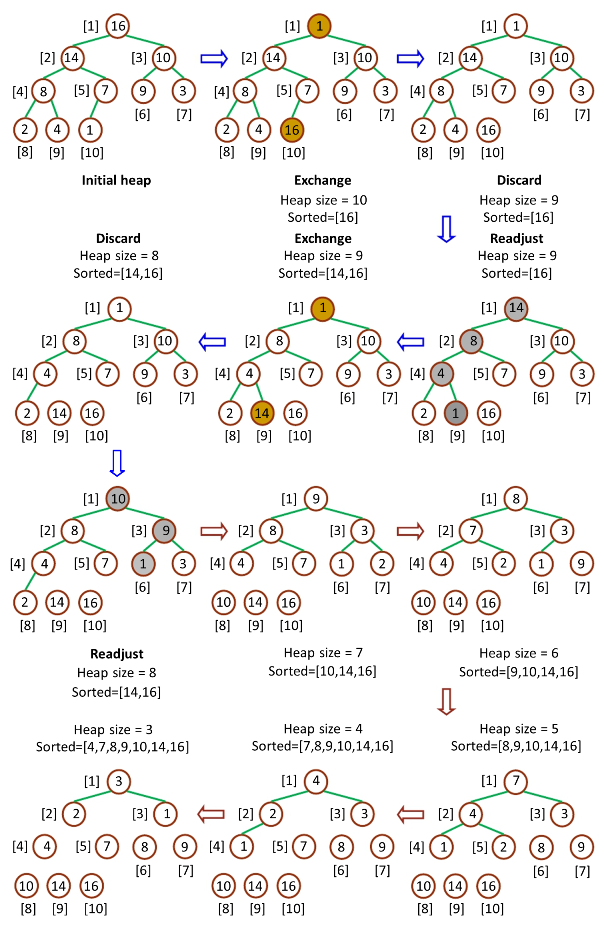
- 堆排序(HeapSort):由于堆是用数组模拟的。得到一个最大根堆后,数组内部并不是有序的。因此需要将堆化数组有序化。思想是总是移除根节点(用最后一个元素来填补空缺),并做最大堆调整的递归运算。第一次将heap[0]与heap[n-1]交换,再对heap[0…n-2]做最大堆调整。第二次将heap[0]与heap[n-2]交换,再对heap[0…n-3]做最大堆调整。重复该操作直至heap[0]和heap[1]交换。由于每次都是将最大的数并入到后面的有序区间,故操作完后整个数组就是有序的了。
- 最大堆调整(Max_Heapify):该方法是提供给上述两个过程调用的。目的是将堆的末端子节点作调整,使得子节点永远小于父节点 。
构造最大堆:先自底向上,再自顶向下
调整最大堆:交换之后,被交换的节点从顶向下调整,调完继续交换,依次递归。
源代码
1 | def heap_sort(ary): |
时空复杂度总结
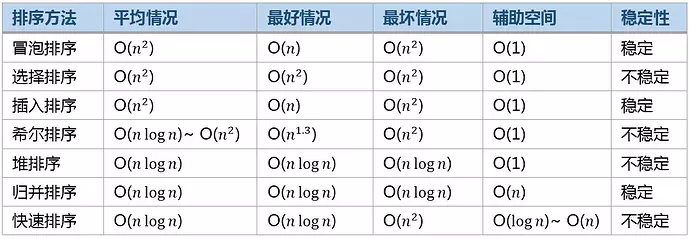
时间复杂度
"快些以O(nlog2n)O(nlog2n)的速度归队"
即快,希,归,堆都是O(nlog2n)O(nlog2n),其他都是O(n2)O(n2),基数排序例外,是O(d(n+rd))O(d(n+rd))
空间复杂度
- 快排O(log2n)O(log2n)
- 归并O(n)O(n)
- 基数O(rd)O(rd)
- 其他O(1)O(1)
稳定性
"心情不稳定,快些找一堆朋友聊天吧"
即不稳定的有:快,希,堆
其他性质
- 直接插入排序,初始基本有序情况下,是O(n)O(n)
- 冒泡排序,初始基本有序情况下,是O(n)O(n)
- 快排在初始状态越差的情况下算法效果越好.
- 堆排序适合记录数量比较大的时候,从n个记录中选择k个记录.
- 经过一趟排序,元素可以在它最终的位置的有:交换类的(冒泡,快排),选择类的(简单选择,堆)
- 比较次数与初始序列无关的是:简单选择与折半插入
- 排序趟数与原始序列有关的是:交换类的(冒泡和快排)