贝叶斯信念网络
基本概念
朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。 解决这个问题的一种算法叫贝叶斯网络(又称贝叶斯信念网络或信念网络)。
贝叶斯网络由两个成分定义:1)有向无环图(DAG); 2)条件概率表的集合(Conditional Probability Table,CPT)
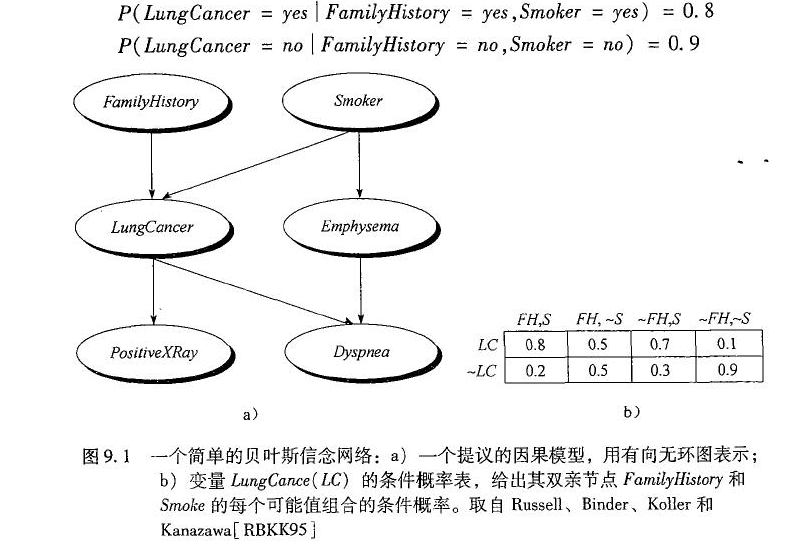
上图给出了一个布尔变量的简单贝叶斯信念网络,图中的弧可看做因果知识。换言之,一旦我们知道变量LungCanner的结果,那么变量FamilyHistory和Smoker就不再提供关于PostiveXRay的任何附近信息。
DAG中每一个节点表示一个随机变量,可以是可直接观测变量或隐藏变量,而有向边表示随机变量间的条件依赖;条件概率表中的每一个元素对应DAG中唯一的节点,存储此节点对于其所有直接前驱节点的联合条件概率。贝叶斯网络有一条极为重要的性质,就是我们断言每一个节点在其直接前驱节点的值制定后,这个节点条件独立于其所有非直接前驱前辈节点。这条特性的重要意义在于明确了贝叶斯网络可以方便计算联合概率分布。 一般情况先,多变量非独立联合条件概率分布有如下求取公式:
而在贝叶斯网络中,由于存在前述性质,任意随机变量组合的联合条件概率分布被化简成
其中,$P(x_1,…,x_n)$是X的值的特定组合的概率,Parents表示xi的直接前驱节点的联合 ,而$P(x_i|Parents(x_i))$的值对应于CPT概率表的值。
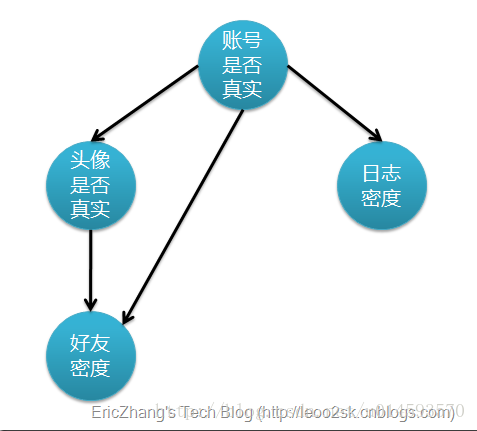
上图是一个有向无环图(DAG) ,不过仅有这个图的话,只能定性给出随机变量间的关系,如果要定量,还需要一些数据,这些数据就是每个节点对其直接前驱节点的条件概率(也就是CPT表的概率),而没有前驱节点的节点则使用先验概率表示。
没有前驱的节点用先验概率表示;以及CPT条件概率,例如P(H=0|R=0)=0.9(真实账号为假,头像也为假的概率)
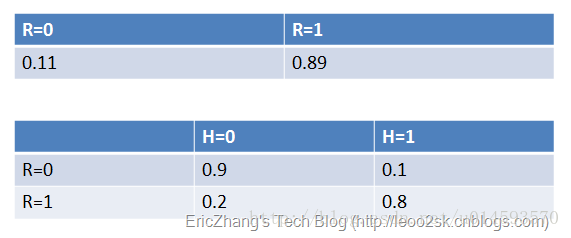
有了这些数据,不但能顺向推断,还能通过贝叶斯定理进行逆向推断。例如,现随机抽取一个账户,已知其头像为假,求其账号也为假的概率:
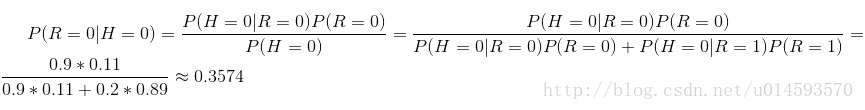
如果给出所有节点的条件概率表,则可以在观察值不完备的情况下对任意随机变量进行统计推断。上述方法就是使用了贝叶斯网络。
训练贝叶斯网络
构造与训练贝叶斯网络分为以下两步:
- 1、确定随机变量间的拓扑关系,形成DAG。这一步通常需要领域专家完成,而想要建立一个好的拓扑结构,通常需要不断迭代和改进才可以。
- 2、训练贝叶斯网络。如果不训练的,我们只能知道定性的网络,而不能定量。实际上这一步也就是要完成条件概率表(CPT表)的构造,如果每个随机变量的值都是可以直接观察的,像我们上面的例子,那么这一步的训练是直观的,方法类似于朴素贝叶斯分类。但是通常贝叶斯网络的中存在隐藏变量节点,那么训练方法就是比较复杂,例如使用梯度下降法。
性能如何
贝叶斯网络已经广泛于临床,生物,征信等领域。其强大之处在于两点
- 1.贝叶斯网络最强大之处在于从每个阶段结果所获得的概率都是数学与科学的反映,换句话说,假设我们了解了足够多的信息,根据这些信息获继而得统计知识,网络就会告诉我们合理的推断。
- 2.贝叶斯网络最很容易扩展(或减少,简化),以适应不断变化的需求和变化的知识。
使用频繁模式分类
关联分类
回顾一下之前的关联规则,显示了规则的置信度和支持度
从分类角度,置信度类似于规则的准准确度。例如,93%的置信度意味着D中身为年轻人并且信誉度为OK的顾客中,93%属于类buysconputer=yes。支持度20%意味着D中20%的顾客是青年,信誉为OK,并且属于类buyscomputer=yes
一般而言,关联规则的分类包括以下步骤:
- 1、挖掘数据,找出频繁项集,即找出数据经常出现的属性-值对
- 2、分析频繁项集,产生每个类的关联规则,它们满足置信度和支持度标准
- 3、组织规则,形成基于规则的分类器
这里,我们考察以下三种分类方法1)CBA ; 2) CMAR ; 3)CPAR
CBA
最早、最简单的关联分类算法是CBA。CBA使用迭代的方法挖掘频繁项集,类似于Apriori算法。CBA使用了一种启发式方法构造分类器,其中规则按照它们的置信度和支持度递减优先级排序,如果当中一组规则具有相同的前件,则选取具有最高置信度的规则代表该集合。在对新元组分类是,使用满足该元组第一个规则对它进行分类。分类器还包含一个默认规则,具有最低优先级。
CMAR
CMAR和CBA在频繁项集挖掘和构建分类器都不同,CMAR采用FP-growth算法的变形来发现满足最小支持的最小置信度的规则完全集。构造分类器时,如果新元组X只匹配一个规则,则简单地把规则的类标号给这个元组。如果多个规则满足X,把这些规则形成一个集合S。CBA将集合S中最大置信度的规则的类标号指派给X,而CMAR考虑多个规则。它根据S的类标号将规则分类,不同组中的规则具有不同的类标号,然后CMAR使用X2X2卡方度量,根据组中规则的统计相关联找出相关性“最强的”规则组,再把该类标号指派个X元组。这样,它就考虑了多个规则,不是像CBA一样只考虑一个规则。CMAR在准确率和复杂的都比CBA更有效一点。
CPAR
CPAR和CMAR相差不多,它通过FOIL算法而不是FP-growth来挖掘规则。同样也将集合S的规则按类分组。然而,CPAR根据期望准确率,使用每组中最好的k个规则预测X元组的类标号,通过考虑组中最好的k个规则而不是所有规则。在大数据集上,CPAR和CMAR准确率差不多,但产生的规则要比CMAR少的多。
基于有区别力的频繁模式分类
如果我们把所有频繁模式都添加到特征空间,可能许多模式是冗余,还可能因特征太多而过分拟合,导致准确率降低。因此,一种好的做法是使用特征选择,删除区别能力较弱的特征,其一般框架步骤(两步法)如下:
- 特征产生:频繁模式的集合F形成候选特征
- 特征选择: 通过信息增等度量对F进行特征选择,得到选择后的频繁模式FsFs,数据集DD变换成D′D′
- 学习分类模型:在数据集D′D′建立分类器
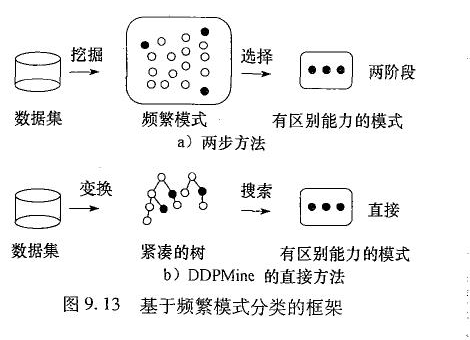
为了提高两步法的效率,考虑将步骤1和步骤2合并为一步。即有可能只挖掘具有高度区别能力的频繁模式的集合,而不是完全集。DDPMine算法采用这种方法,它首先把训练数据变换到一个称频繁模式树或FP树的紧凑树结构,然后再该树种搜索有区别能力的模式。
在准确率和效率两个方面,DDPMine都优于最先进的关联分类方法。
k-近邻分类
对于,k-近邻分类算法,位置元组每次都被指派到它的k个最近邻(距离度量)的多数类。