R导论学习笔记(九):编写函数
1 | `一个函数是通过下面的语句形式定义的,` |
1 | `%anything %将以二元操作符(binary operator)的形式在表达式中使用,而不是函数的形式。例如我们用! 作为中间的字符。函数可以如下定义` |
1 | `注意任何在函数内部的普通赋值都是局部的暂时的,当退出函数时都会丢失。如果想在一个函数里面全局赋值或者永久赋值,可以采用“强赋值”(superassignment)操作符<<- 或者采用函数assign()` |
1 | `在众多泛型函数中,plot() 用于图形化显示对象,summary()用于各种类型的概述分析,以及anova() 用于比较统计模型。可以用函数methods() 得到当前对某个类对象可用的泛型函数列表.` |
R导论学习笔记(八):概率分布和条件语句
R 的统计表
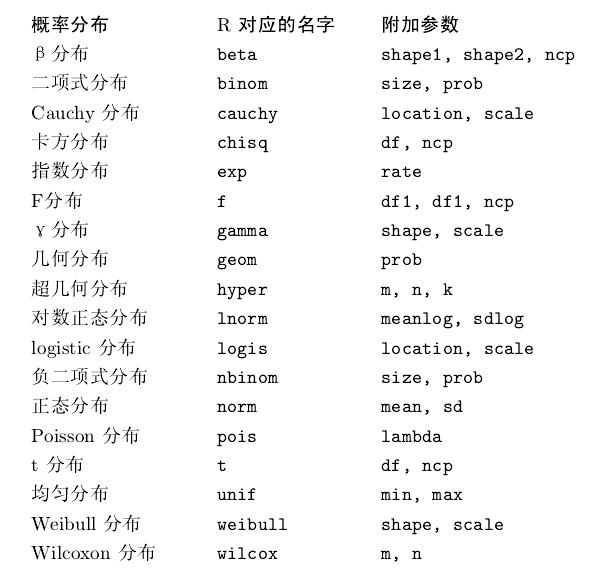
不同的名字前缀表示不同的含义,d表示概率密度函数,p 表示累积分布函数(cumulative distribution function,CDF),q 表示分位函数以及r 表示随机模拟(random deviates)或者随机数发生器
1 | 我们可以用很多方法分析一个单变量数据集的分布。最简单的办法就是直接看数字。利用函数summary 和fivenum 会得到两个稍稍有点差异的汇总信息。 此外,stem(“茎叶”图)也会反映整个数据集的数字信息。用函数hist 绘制柱状图。 |
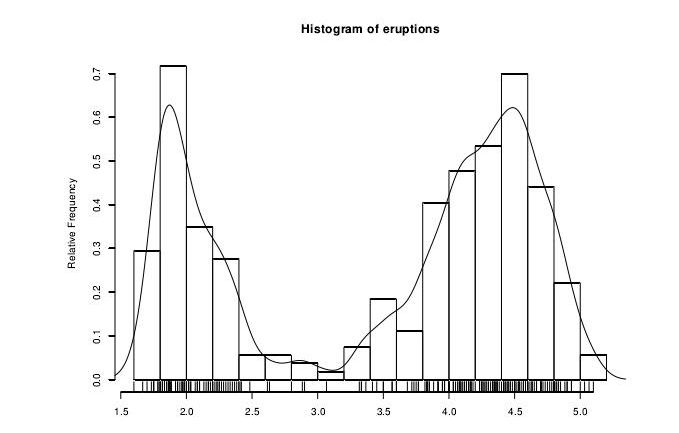
函数ecdf 绘制一个数据集的经验累积分布(empirical cumulativedistribution)函数。
分位比较图(Quantile-quantile (Q-Q) plot),又称QQ图,通常用于检验是否满足正态分布
1 | # 检验是否符合正态分布 |
1 | 利用Shapiro-Wilk方法进行正态检验 |
1 | 到现在为止,我们已经学会了单样本的正态性检验。而更常见的操作是比较两个样本的特征。在R 里面,所有“传统”的检验都放在包stats 里面。这个包常常会自动载入。 |
简单来说,通过把所得到的统计检定值与统计学家建立了一些随机变量的概率分布进行比较,证明样本的统计结果不是随机得到的,是有意义的。专业上,P值或sig值为结果可信程度的一个递减指标,如p=0.05提示样本中变量关联有5%的可能是由于偶然性造成的。即假设总体中任意变量间均无关联。
1 | R 语言的条件语句形式为 |
R导论学习笔记(七):从文件中读取数据
1 | read.table()函数 |
1 | `假定有三个数据向量` |
1 | data() 访问内部标准数据集为了 |
1 | `用edit 调用数据框和矩阵时,R 会产生一个电子表形式的编辑环境。这对在数据集上进行小的修改时非常有用的。它的命令是> xnew <- edit(xold)` |
R导论学习笔记(六):列表和数据框
1 | 下面的例子演示怎么创建一个列表: |
1 | `分量常常会被编号的(numbered),并且可以利用这种编号来访问分量。如果列表 Lst 有四个分量,这些分量则可以用Lst[[1]], Lst[[2]], Lst[[3]] 和Lst[[4]]独立访问。如果Lst[[4]] 是一个有下标的数组,那么Lst[[4]][1] 就是该数组的第一个元素。` |
1 | 列表的分量可以被命名,这种情况下可以通过名字访问。此时,可以把字符串形式的分量名字放在列表名后面的双中括号中,或者干脆采用下面的形式 |
1 | 可以通过函数list() 将已有的对象构建成列表。下面的命令 |
1 | `数据框常常会被看作是一个由不同模式和属性的列构成的矩阵。它能以矩阵形式出现,行列可以通过矩阵的索引习惯访问。可以通过函数data.frame 创建符合上面对列(分量)限制的数据框对象:> accountants <- data.frame(home=statef, loot=incomes, shot=incomef)` |
1 | `从外部文件读取一个数据框最简单的方法是使用函数read.table()` |
1 | 用$ 符号访问对象不是非常的方便,如accountants$statef。一个非常有用的工具将会使列表或者数据框的分量可以通过它们的名字直接调用。而且这种调用是暂时性的,没有必要每次都显式的引用列表名字。函数attach() 除了可以用目录路径作为参数,也可以使用数据框。假定数据框lentils 有三个变量lentils$u, lentils$v, lentils$w,那么 |
1 | `如何使用数据框• 处理问题时,将相应的数据框绑定在位置2上,在第1 层的工作目录中存放操作值和临时变量;• 问题结束时,用$ 形式的赋值命令把任何你想保留的变量加入数据框中,然后利用函数detach() 将绑定去除;• 最后去掉工作目录中所有你不想要的变量,尽可能清空临时变量。` |
R导论学习笔记(五):数组和矩阵
1 | `数组和矩阵的联系:一个矩阵只是一个二维的数组` |
1 | `向量只有在定义了 dim 属性后才能作为数组在R 中使用。假定,z是一个含1500个元素的向量。那么> dim(z) <- c(3,5,100)对dim 属性的赋值使得该向量成一个3 ×5 ×100 的数组。` |
1 | `数据向量(data vector)的值在数组中的排列顺序采用 FORTRAN 方式的数组元素次序,即“按列次序”,也就是说第一下标变化最快,最后下标变化最慢。假定数组a的维数向量是c(3,4,2),则a 中有3×4×2 = 24 元素,依次为a[1,1,1],a[2,1,1], ..., a[2,4,2], a[3,4,2]。` |
1 | 延续前面的例子,a[2,,] 是一个4 × 2 的数组。它的维度向量为c(4,2),数据向量依次包括下面的值 |
1 | a[,,]表示整个数组。这和忽略下标直接使用a 效果是一样的 |
1 | 假定我们有一个4 ×5 的数组X,我们可以做如下的事情: |
1 | `cbind和rbind分别是根据列和行合并,例如ib <- cbind(1:5, 2)> ib [,1] [,2][1,] 1 2[2,] 2 2[3,] 3 2[4,] 4 2[5,] 5 2` |
1 | 在R中求单变量的频次,直接使用table函数就可以了,比如: |
1 | `除了用设定一个向量dim 属性的方法来构建数组,它还可直接通过函数array 将向量转换得到,具体格式为> Z <- array(data vector , dim vector )> Z <- array(0, c(3,4,2))这样就会使得Z 是一个所有值都是0的3 ×4 ×2 数组` |
1 | `数组可用于算术表达式中,并且结果就是一个基于数据向量的对应元素运算而得到的数组。所有操作数的属性dim 必须一致` |
1 | 所谓数组(或向量)a和b的外积,指的是a的每一个元素和b的每一个元素搭配在一起相乘得到的新元素.当然运算规则也可自定义.外积运算符为 %o%(注意:百分号中间的字母是小写的字母o),也可以用> ab <- outer(a, b, "*") |
1 | 广义转置:我们可以用命令B <- t(A)表示矩阵A转置,函数nrow(A) 和ncol(A) 将会分别返回矩阵A 的行数和列数。 |
1 | A*B表示矩阵元素对应相乘(要求行列相同),A%*%B表示矩阵乘法,行列式用法(要求满足m,k × k,n)。 |
1 | `函数crossprod() 可以完成“矢积”(crossproduct)运算,也就是说crossprod(X,y) 和t(X) %*% y 等价,但是在运算上更为高效.如果crossprod() 第二个参数忽略了,它将默认和第一个参数一样,即第一个参数和自己进行运算` |
1 | `函数diag() 的含义依赖于它的参数。当v 是一个向量时,diag(v)返回以该向量元素为对角元素的对角矩阵。当M 是一个矩阵时,diag(M) 返回M的对角元素。这和Matlab 中diag() 的用法完全一致。不过有点混乱的是,如果k 是单个值,那么diag(k) 的结果就是k ×k 的方阵!` |
1 | `求解线性方程组是矩阵乘法的逆运算。当下面的命令运行后,> b <- A %*% x(想象多元方程组形式,A的行数为样本数)。如果仅仅给出A 和b,那么x 就是该线性方程组的根。在R 里面,用命令> solve(A,b)求解线性方程组,并且返回x (可能会有一些精度丢失)。注意,在线性代数里面该值表示为x = A−1b ,其中A−1表示A的逆(inverse)。矩阵的逆可以用下面的命令计算,solve(A)不过一般很少用到。在数学上,用直接求逆的办法解x <- solve(A) %*% b相比solve(A,b)不仅低效而且还有一种潜在的不稳定性。用于多元计算的二次型xA−1x可以通过像x %*% solve(A,x)的方式计算得到,而不是直接计算A 的逆。` |
1 | 函数eigen(Sm) 用来计算矩阵Sm 的特征值和特征向量。这个函数的返回值是一个含有values 和vectors 两个分量的列表。ev$val 表示Sm 的特征值向量ev$vec 则是相应特征向量构成的一个矩阵。假定我们仅仅需要特征值,我们可以采用如下的命令: |
1 | `函数svd(M) 可以把任意一个矩阵M作为一个参数, 且对M 进行奇异值分解。这包括一个和M 列空间一致的正交列U 的矩阵,一个和M 行空间一致的正交列V 的矩阵,以及一个正元素D 的对角矩阵,如M = U %*% D %*% t(V)` |
1 | 函数lsfit() 返回最小二乘法拟合(Least squares fitting)的结果列表。赋值可以采用入下命令 |
1 | 单个因子会把各部分数据分成不同的组。类似的是,一对因子可以实现交叉分组等。 函数table() 可以从等长的不同因子中计算出频率表。如果有k 个因子参数,那么结果将是一个k-维的频率分布数组。假定statef 是一个设定数据向量元素个体所在州的因子,那么下面的赋值 |
R导论学习笔记(四):有序因子和无序因子
1 | `因子(factor)是一个对等长的其他向量元素进行分类(分组)的向量对象。 R同时提供有序(ordered)和无序(unordered)因子。` |
1 | 注意在字符向量中,“有序”意味着以字母排序的。因子可以简单地用函数factor() 创建: |
1 | 函数levels() 可以用来得到因子的水平(levels),相当于分类依据因子 |
1 | 使用因子来计算样本中每个州的平均收入的一个例子: |
1 | `有时候因子的水平有自己的自然顺序并且这种顺序是有意义的。我们需要记录下来可能在进一步的统计分析中用到。函数ordered() 就是用来创建这种有序因子。在其他方面,函数ordered() 和factor 基本完全一样。大多数情况下,有序和无序因子的唯一差别在于前者显示的时候反应了各水平的顺序。另外, 在线性模型拟合的时候,两种因子对应的对照矩阵的意义是完全不同的。` |
R导论学习笔记(三):对象
1 | `R 的对象类型包括数值型(numeric),复数型(complex),逻辑型(logical),字符型(character)和原味型(raw)。向量必须保证它的所有元素是一样的模式。因此任何给定的向量必须明确属于逻辑性,数值型,复数型,字符型或者原味型。注意空向量也有自己的模式。例如,空的字符串向量将会被显示character(0) 和空的数值向量显示为numeric(0)。` |
1 | `一个对象的模式(mode)是该对象基本要素的类型,另外一个所有对象都有的特征是长度(length),模式和长度又叫做一个对象的“内在属性”。` |
1 | `例如,如果z 是一个长为100 的复数向量,那么命令mode(z) 就会得到字符串"complex" 而length(z) 对应的是100。` |
1 | 有一系列类似as.something() 的函数,这些函数主要用于对象模式数据的强制转换,例如> digits <- as.character(z) # 转为字符形式 |
1 | 改变对象长度这一点上,一个“空”的对象仍然有其模式的。例如> e <- numeric()创建了一个数值模式的空向量结构e。类似的是,character()是一个空的字符向量,等等。一旦一个任意长度的对象被创建,新元素可以通过给定一个在先前索引范围外的索引值而加入。因此> e[3] <- 17将创建一个长度为3的向量e(此时,前两个元素都是NA)。相反,删减一个对象的大小只需要用赋值操作。因此,如果alpha 是一个长度为10的对象,那么> alpha <- alpha[2 * 1:5]将创建一个由偶数索引位值上的元素构成的长度为5的对象(此时,老的索引将会被抛弃)。我们可以用下面命令仅仅保留起始的三个值> length(alpha) <- 3一个向量也可以用同样的办法扩充(扩充部分用缺损值)。 |
R导论学习笔记(二):算术操作和向量运算
1 | 假如我们要创建一个含有五个数值的向量x,且这五个值分别为10.4,5.6,3.1,6.4 和21.7,则 R 中的命令为 |
1 | 在算术表达式中使用向量将会对该向量的每一个元素都进行同样算术运算。出现在同一个表达式中的向量最好是长度一致。如果他们的长度不一样,该表达式的值将是一个和其中最长向量等长的向量。表达式中短的向量会被循环使用(recycled)(可能是部分的元素)以达到最长向量的长度。利用前面例子中的变量,命令 |
1 | `sum(x)给出x 中元素的累加和, 而prod(x) 则得到它们的乘积。var(x)则计算样本方差` |
1 | 如果var() 的参数是一个n×p 的矩阵,则将该矩阵行与行之间看作是相互独立的p-变量的样本向量,从而得到一个p×p 的样本协方差矩阵。 |
1 | 函数seq() 是数列生成中最为常用的工具。它有五个参数,起始的两个参数,表示一个数列的首尾。如果只是给定这两个值,则和冒号运算符的效果完全一样了。前两个参数就可以用from=value 和to=value 方式设定; |
1 | 还有一个相关的函数是rep()。 它可以用各种复杂的方式重复一个对象。最简单的方式是 |
1 | 逻辑向量元素可以被赋予的值有TRUE,FALSE 和NA (“不可得到”)逻辑向量可以由条件式(conditions)产生。例如 |
1 | `函数is.na(x) 返回一个和x 同等长度的向量。它的某个元素值为TRUE 当且仅当x中对应元素是NA。` |
1 | `特别要注意的是逻辑表达式x == NA 和is.na(x) 完全不同。因为NA 不是一个真实的值而是一个符号以表示某个量是不可得到的, 因此x == NA 得到的是一个长度和x一致的向量。它的所有 元素的值都是NA.` |
1 | `总之,对于NA 和Na N(数学上无法计算得到) 用is.na(xx) 检验都是 TRUE。为了区分它们,is.nan(xx)就只对是Na N 元素显示TRUE。` |
1 | `通过函数c() 可以把几个字符向量连接成一个字符向量;函数paste() 可以有任意多的参数,并且把它们一个接一个连成字符串。这些参数中的任何数字都将被显式地强制转换成字符串,而且以同样的方式在终端显示。默认的分隔符是单个的空格符,不过这可以被指定的参数修改。参数sep=string 就是将分隔符换成string,这个参数可以设为空。例如,> labs <- paste(c("X","Y"), 1:10, sep="")使得labs 变成一个字符向量。c("X1", "Y2", "X3", "Y4", "X5", "Y6", "X7", "Y8", "X9", "Y10")` |
1 | `负整数向量索引。这种索引向量指定被排除的元素而不是包括进来。> y <- x[-(1:5)] #将x 除开始五个元素外的其他元素都赋给y。` |
1 | 字符串向量索引,这可能仅仅用于一个对象可以用names 属性来识别它的元素。 |
R导论学习笔记(一):基础
记录读《R导论》和《153分钟学会R》 的学习笔记
如果你是第一次在UNIX 系统使用 R,我们推荐的操作步骤如下:
- 创建一个独立的子目录work 来保存你要在这个系统上用 R 分析的数据文件。当你用 R 处理这些数据时,这将是你的工作目录。
1 | $ mkdir work |
用命令启动 R 程序。
1
$ R
此时,可以键入 R 的命令(见后面的内容)。
退出 R 程序的命令是
1
>q()
1 | 为了得到任何特定名字的函数的帮助,如solve,可以使用如下命令 > help(solve) |
1 | 在大多数 R 平台中,你可以通过运行下面的命令得到HTML 格式的帮助。 > help.start() |
1 | 命令可以被(;)隔开,或者另起一行。基本命令可以通过大括弧({和}) 放在一起构成一个复合表达式(compound expression)。注释几乎可以放在任何地方。一行中,从井号(#)开始到句子收尾之间的语句就是注释。 |
1 | 如果一批命令保存在工作目录work 下一个叫commands.R 的文件中,可以用下面的命令在 R 会话中执行这个文件。 > source("commands.R") |
1 | 如何清除变量?清除单个变量使用 rm() 函数,清除内存中所有的变量: |
1 | 如何得到函数的代码?通常情况你只需要在 R 平台下写出你需要查看的函数名,回车即可。比如: |
1 | 但有时候这个函数可能是一个泛型函数(Generic Function),上面的方法就需要稍稍改进一下:先使用 methods() 函数来查看这个类函数的列表,找到具体需要的函数,写出来,回车 ,问题解决。 |
1 | summary # It i s a generic funciton |
1 | 想查看一个矩阵的前(后)几行, 么办?可以使用 head() 或 tail() 函数。 |
1 | 在 R 中公式的符号都是什么意义? |
1 | 可以将 R 中显示的结果输出到文件么?可以。使用 sink()函数。 |
1 | 怎样将因子 (factor) 转换为数字 |
1 | 为什么当我使用 source() 时,不能显示输出结果? |
1 | 在 R 里面使用必须使用双反斜杠或单斜杠表示文件路径,比如: |
1 | 如何删掉缺失值? |
1 | 如何将字符串转变为命令行? |
1 | 如何向一个向量 加元素?参考 append()函数。 |
1 | 我的数据框有相同的行,如何去掉这些行? |
1 | 如何对数列(array)进行维度变换? |
1 | 如何删除 list 中的元素? |
1 | 如何对矩阵 行 (列) 作计算?使用函数 apply() |
1 | 如何注掉大段的 R 程序 |
1 | 一组数中随机抽取数据?参考函数 sample() |
1 | 如何根据共有的列将两个数据框合并? |
1 | 如何求矩阵各行 (列) 的均值? |
1 | 如何计算组合数或得到所有排列组合? |
1 | 如何在 R 里面求(偏)导数? |
1 | 如何模拟高斯(正态)分布数据? |
1 | 如何在字符串中选取特定位置的字符? |
1 | 这里要区别一下 length,length 函数是返回向量里元素的个数。比如 “你好吗” 是长度为一的向量,但这个元素的字符长度为三,这里就需要使用 nchar 函数: |
1 | 如何在同一面出多张图? |
1 | 如何在条形图上显示每个 bar 的数值? |
1 | 没有直接计算峰度和偏度的函数?当然自己写一个也费不了太多时间。FBasics 包中提供了可以直接计算偏度和峰度的函数。 |
1 | 如何得到一个正态总体均值µ的区间估计?很简单,t.test() 函数 |
1 | 如何做聚类分析? |
1 | 如何做主成分分析? |
1 | 如何对样本数据进行正态检验?比较常见的方法: |
1 | 如何做配对 t 检验?参考 t.test() 中的 paired 参数 |
1 | 多项式回归应该使用什么函数?使用 I() ,例如: |
如何使用方差分析(ANOVA)?
方差分析同线性回归模型很类似,毕竟它们都是线性模型。最简单实现方差分析的函数为aov(),通过规定函数内公式形式来指定方差分析类型:

1 | 如何求解没有常数项的线性回归模型?只需在公式中引入 0 即可 : |
1 | 回归的命令是?参考 MASS 包中的 lm.ridge() 函数。 |
1 | `如何使用正交多项式回归?在 R 中,使用 poly() 函数:( z <− poly (1:10 , 3))` |
1 | 如何求 Spearman 等级(或 kendall)相关系数? |
1 | `如何做 Decision Tree?基于树型方法的模型(Tree-based model)并不被统计学背景的研究者所熟悉,但它在其他领域却时常被广泛应用。下面是 Modern Applied Statistics With S 中的例子,需要加载 rpart包。l i b r a r y ( rpart )set . seed (123)cpus . rp <− rpart ( log10 ( perf ) ~ . , cpus [ , 2 : 8 ] , cp = 1e−3)plot ( cpus . rp , uniform = T)text ( cpus . rp , d i g i t s = 3)` |
1 | box-cox 变换?MASS 包中的boxcox ()函数。 |
1 | R 有类似于 SPSS 的界面么?有!安装包 Rcmdr ,加载包后,使用命令Commander() |
1 | `样来计算函数运行使用时间?使用 system.time() 。proc.time() 可以获得 R 进程存在的时间,system.time() 通过调用两次 proc.time() 来计算函数运行的时间。` |